# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# statisticsimport statsmodels.api as sm# pandas optionspd.set_option('mode.copy_on_write', True) # pandas 2.0pd.options.display.float_format ='{:.2f}'.format# pd.reset_option('display.float_format')pd.options.display.max_rows =7# max number of rows to display# NumPy optionsnp.set_printoptions(precision =2, suppress=True) # suppress scientific notation# For high resolution displayimport matplotlib_inlinematplotlib_inline.backend_inline.set_matplotlib_formats("retina")
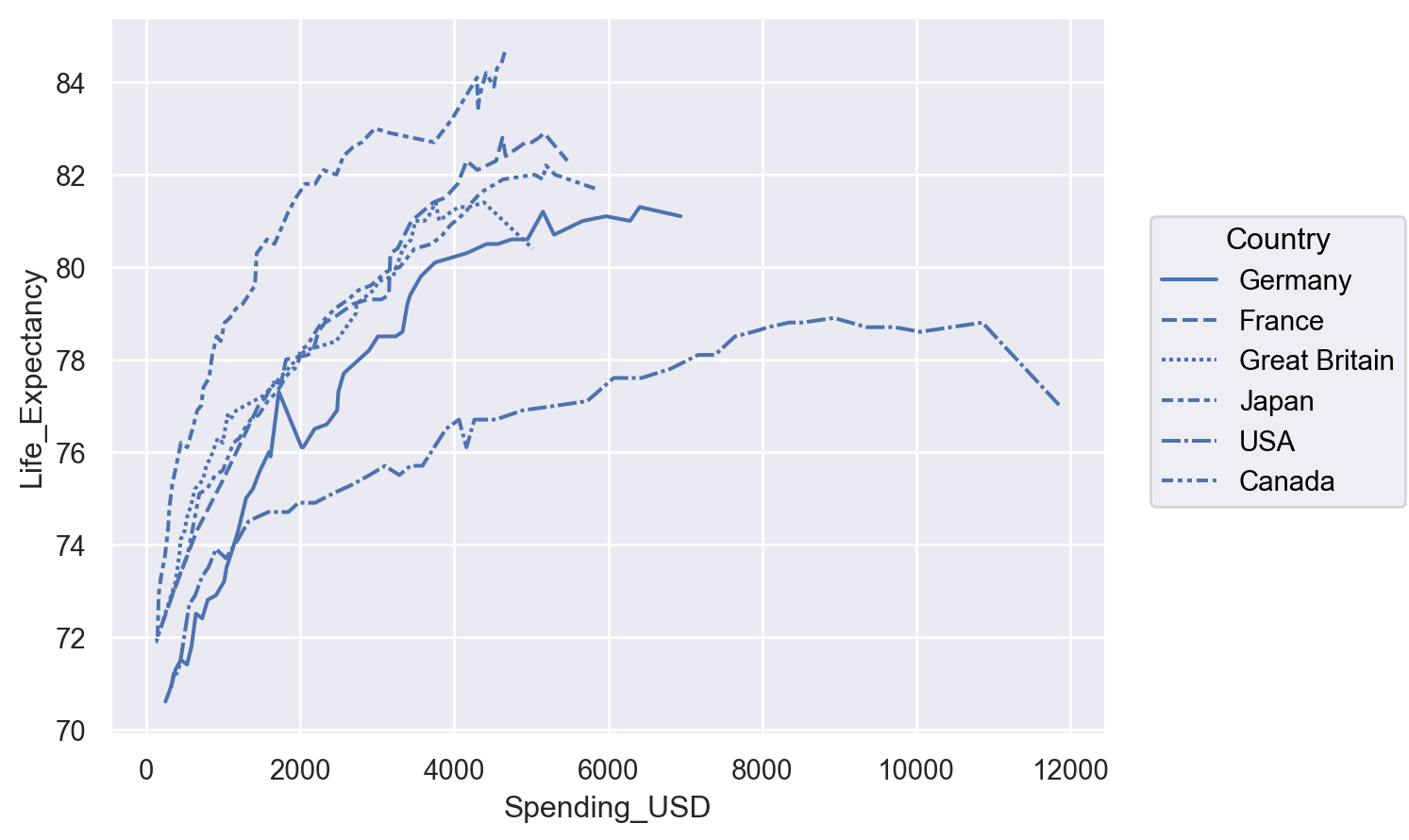
Data: Fuel economy data from 1999 to 2008 for 38 popular models of cars
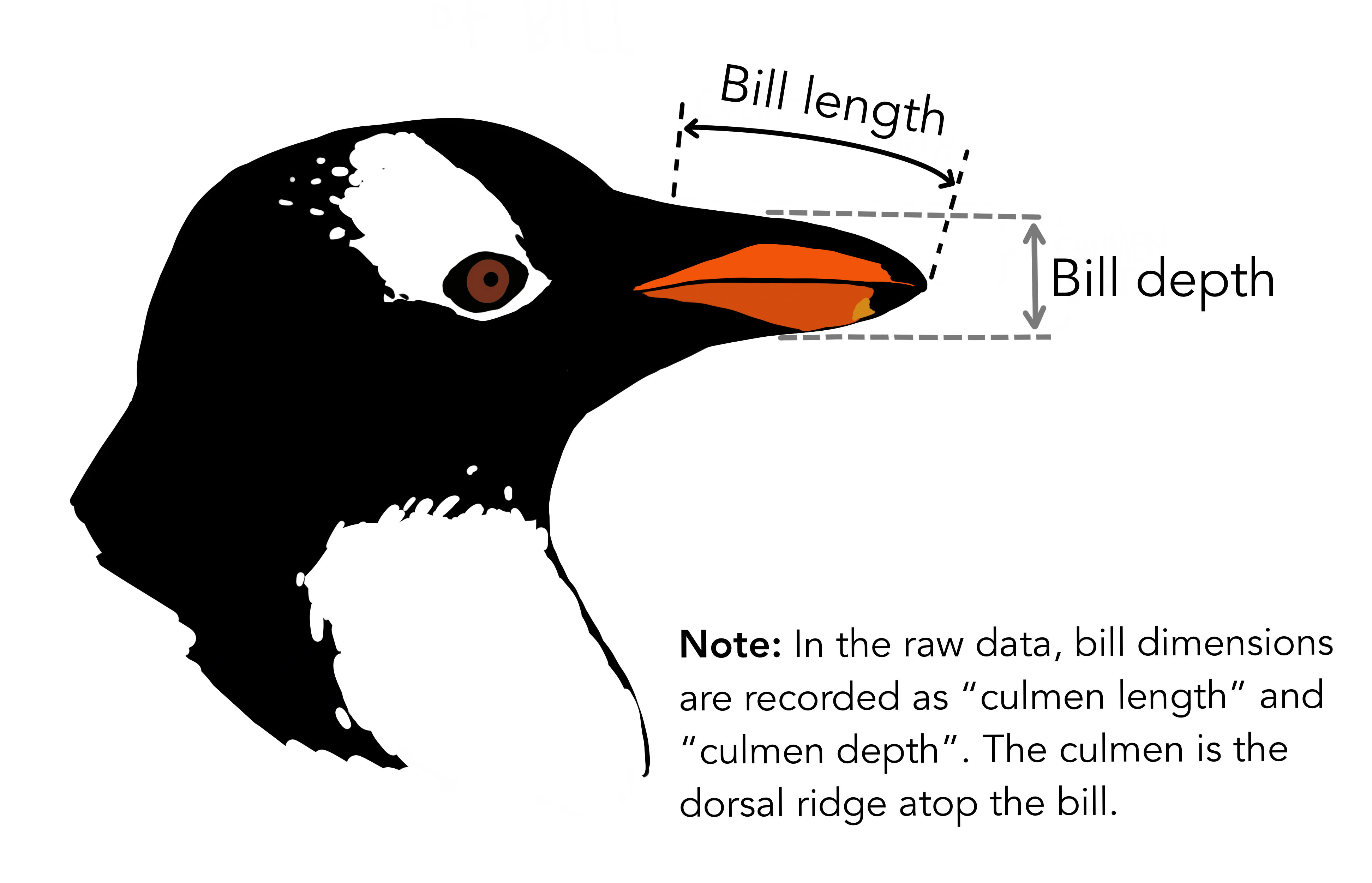
mpg 데이터셋
아래 코드에서 statsmodels에서 mpg데이터가 파이썬 버전에 상관없이 잘 받아지니 신경쓰지 마시길…
# import the datasetmpg_data = sm.datasets.get_rdataset("mpg", "ggplot2")mpg = mpg_data.data
# Descriptionprint(mpg_data.__doc__)
mpg
manufacturer model displ year cyl trans drv cty hwy fl \
0 audi a4 1.80 1999 4 auto(l5) f 18 29 p
1 audi a4 1.80 1999 4 manual(m5) f 21 29 p
2 audi a4 2.00 2008 4 manual(m6) f 20 31 p
.. ... ... ... ... ... ... .. ... ... ..
231 volkswagen passat 2.80 1999 6 auto(l5) f 16 26 p
232 volkswagen passat 2.80 1999 6 manual(m5) f 18 26 p
233 volkswagen passat 3.60 2008 6 auto(s6) f 17 26 p
class
0 compact
1 compact
2 compact
.. ...
231 midsize
232 midsize
233 midsize
[234 rows x 11 columns]
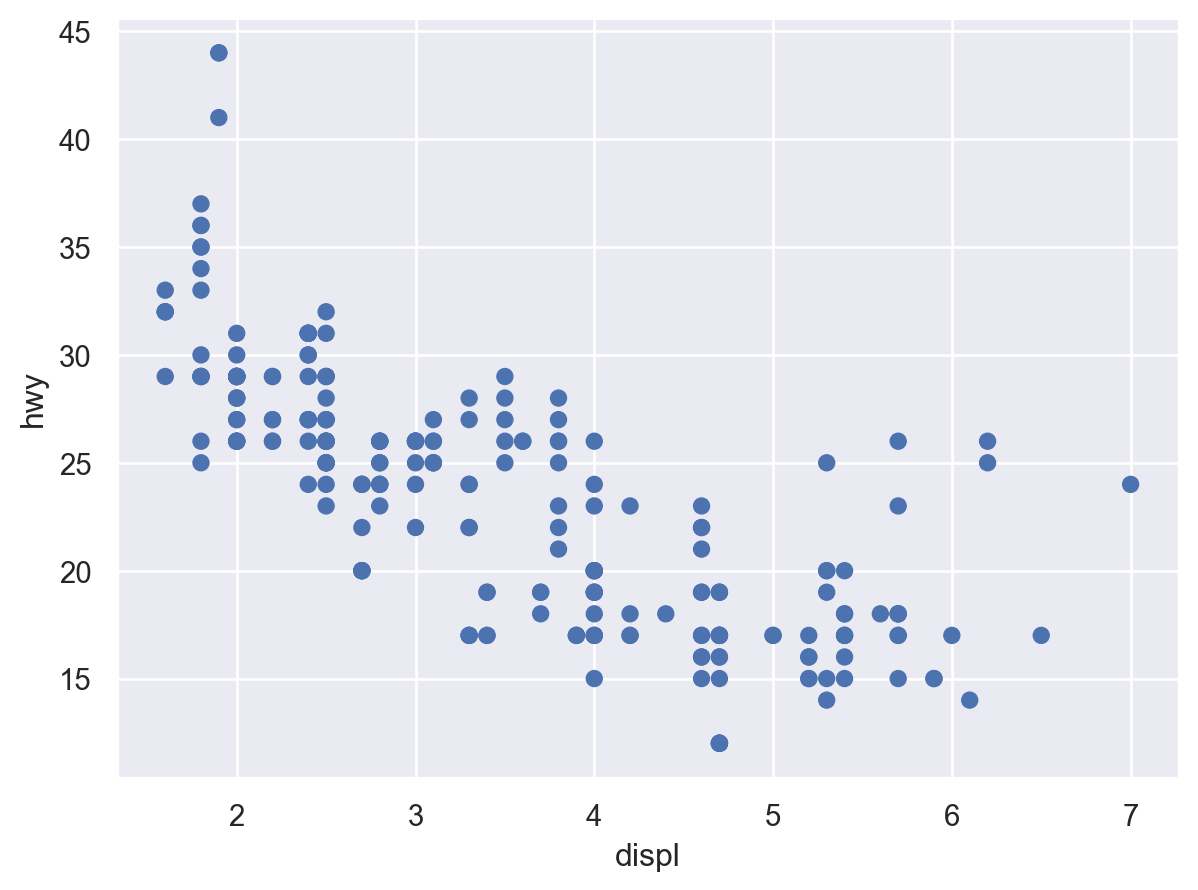
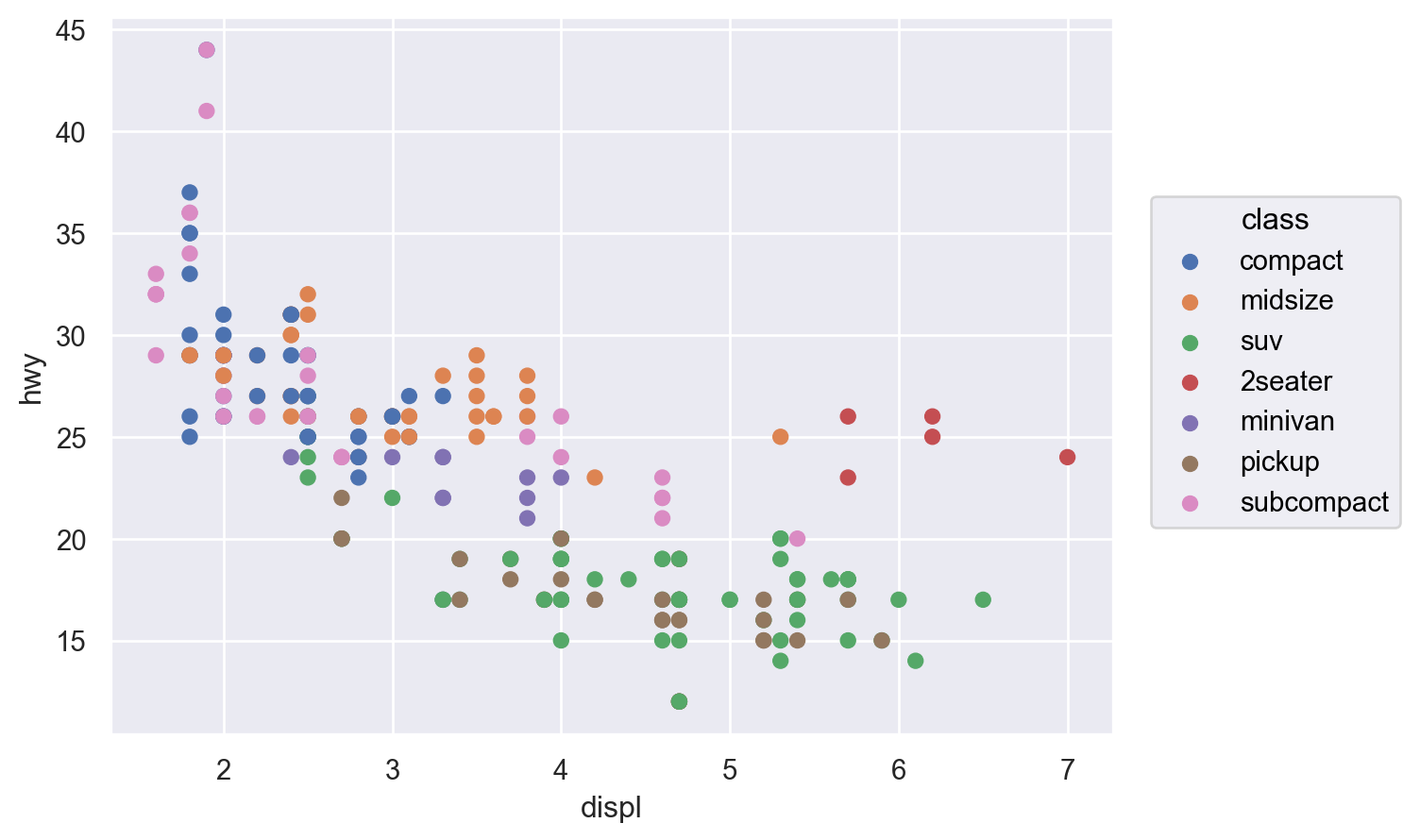
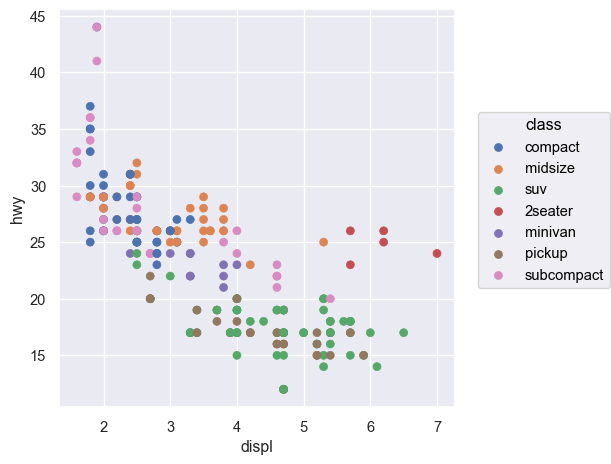
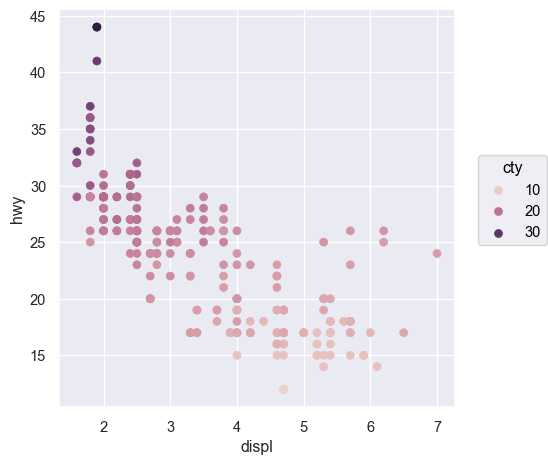
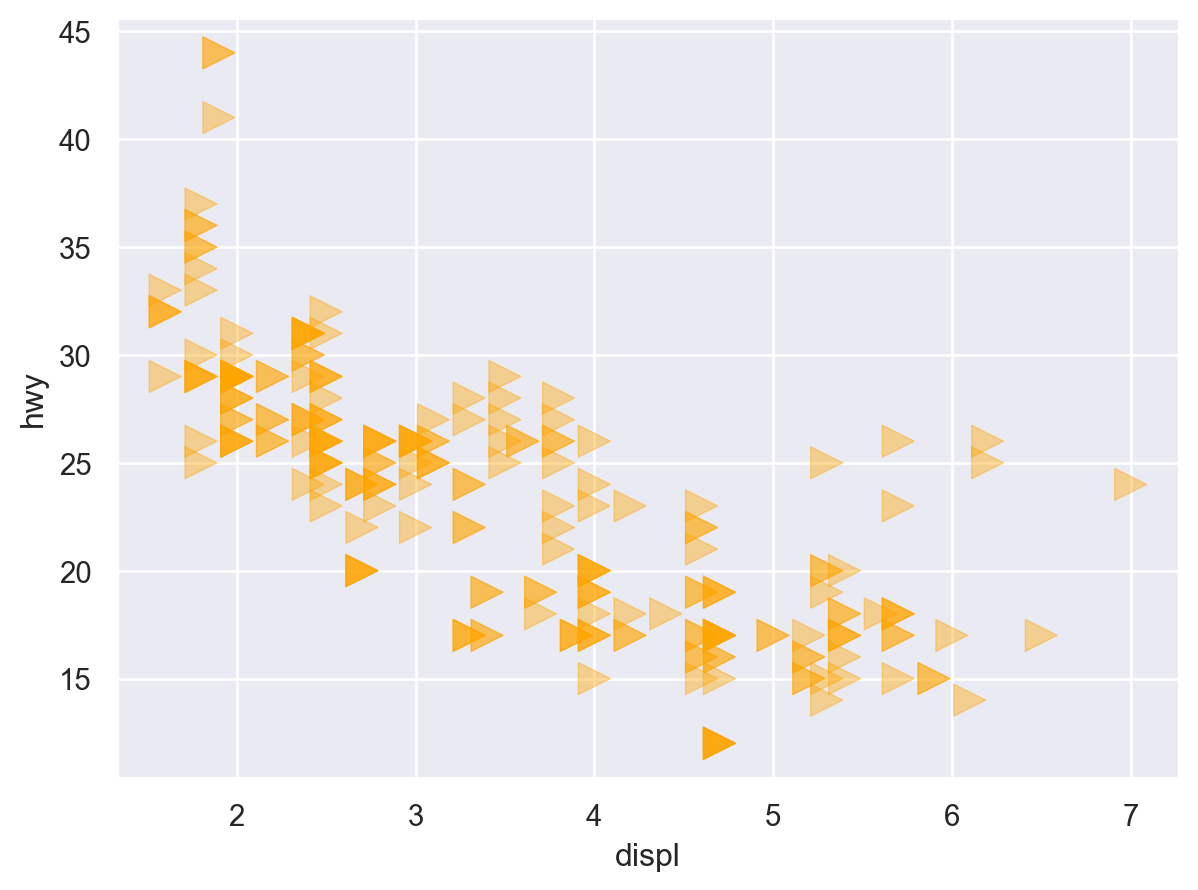
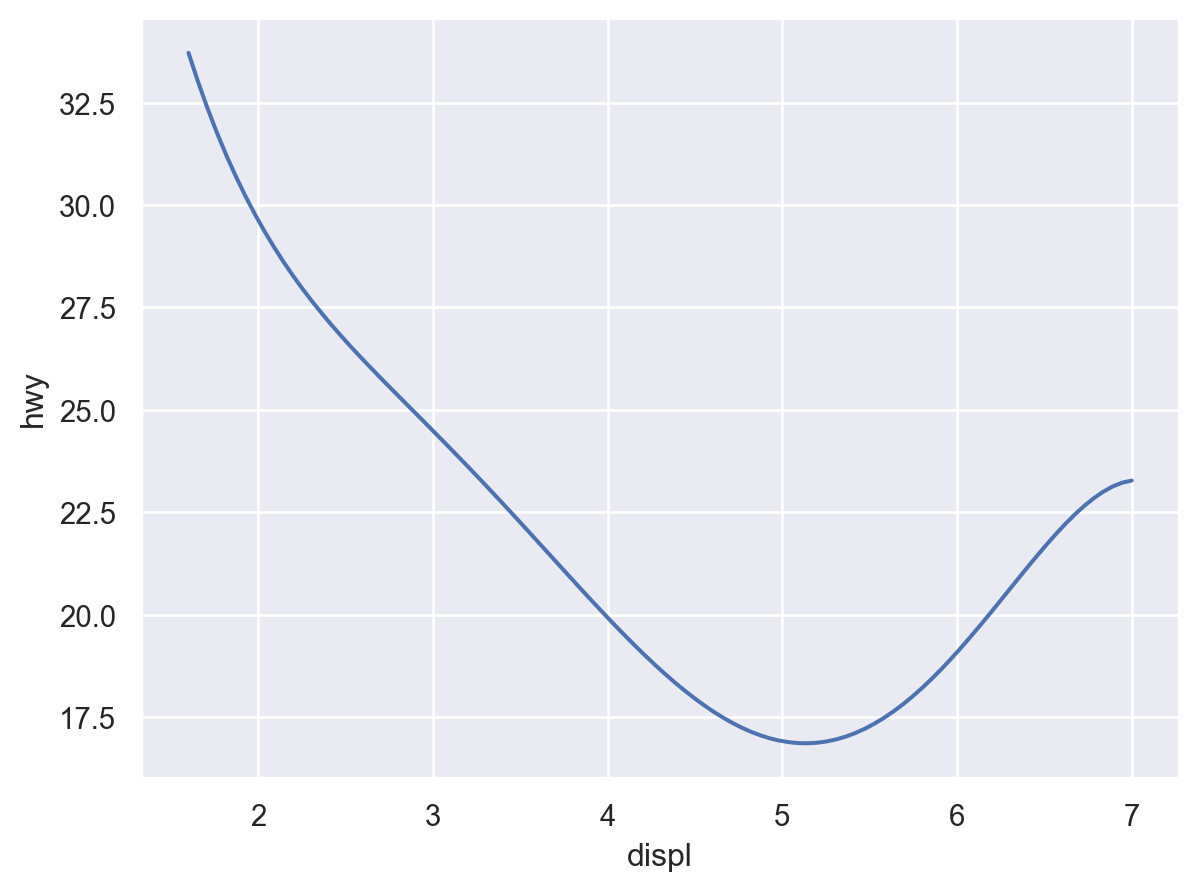
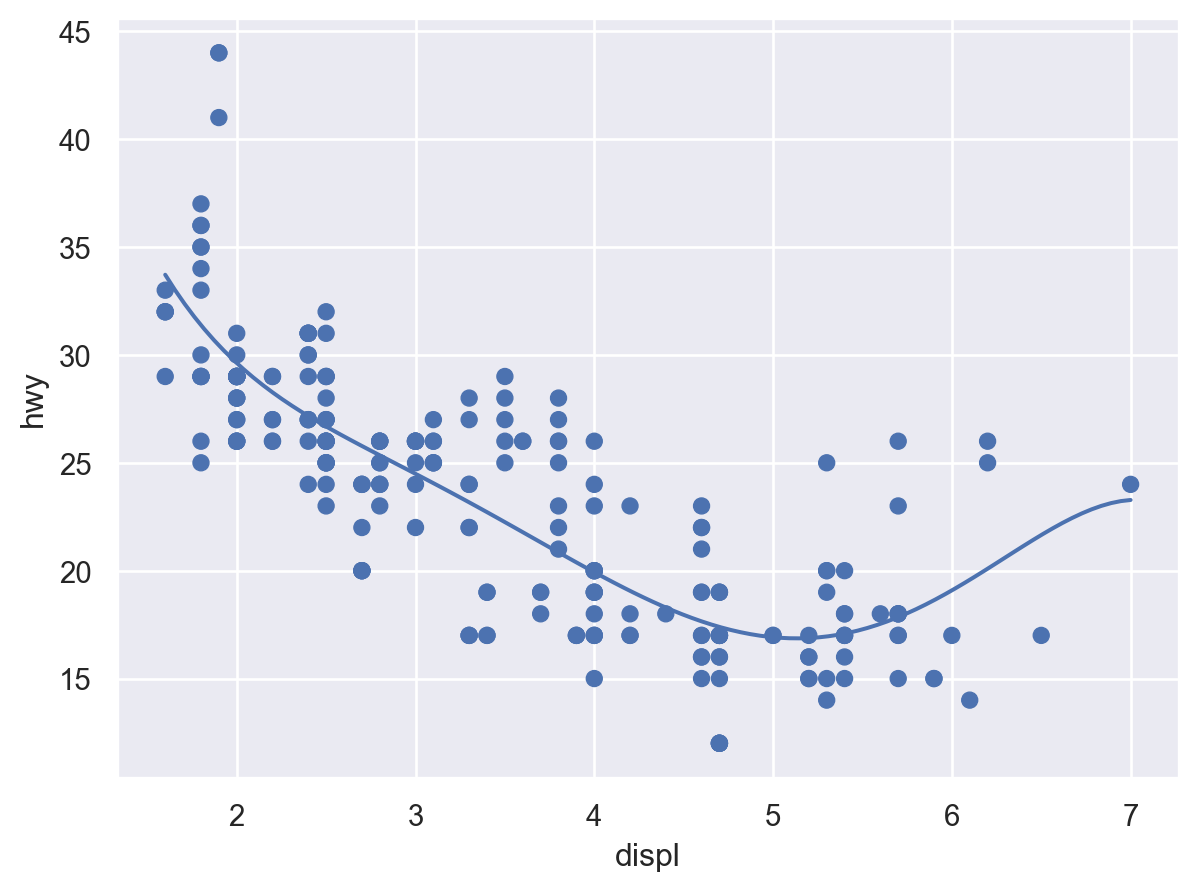
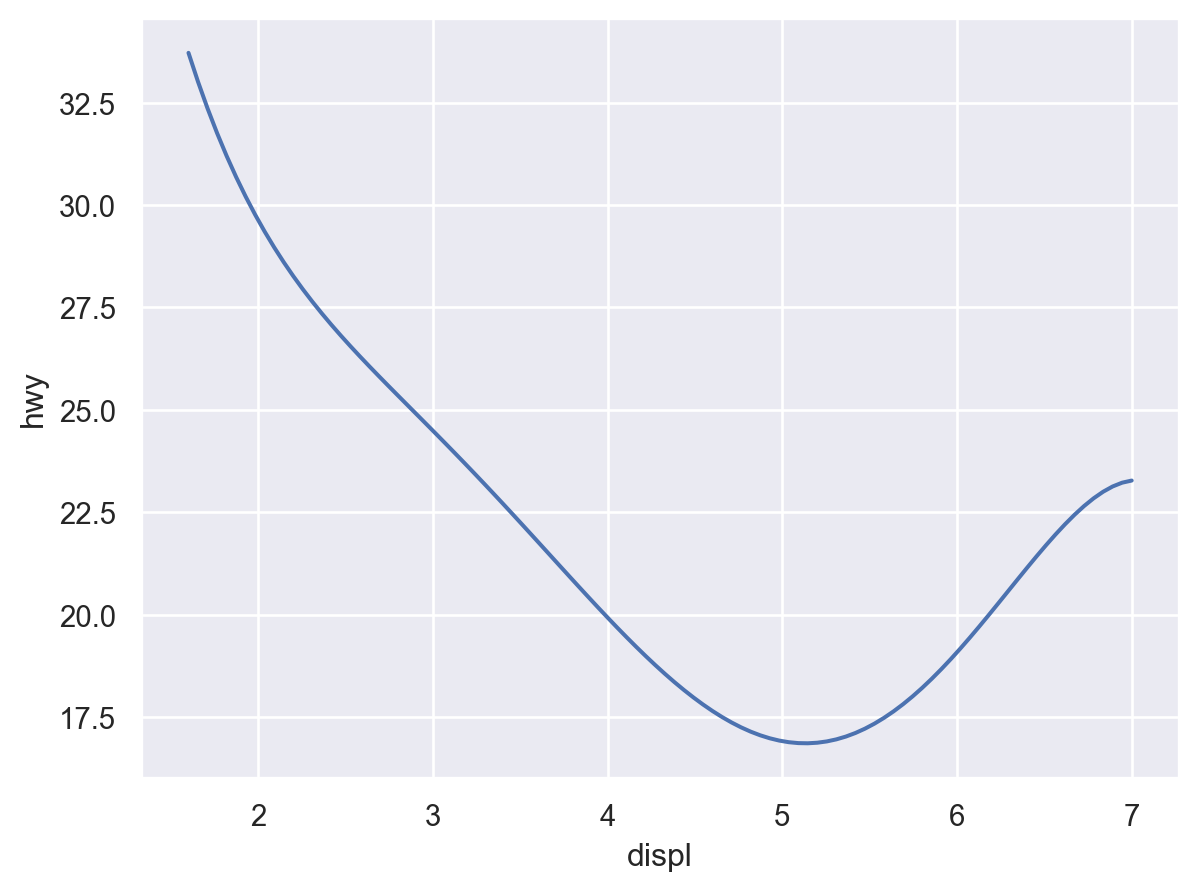
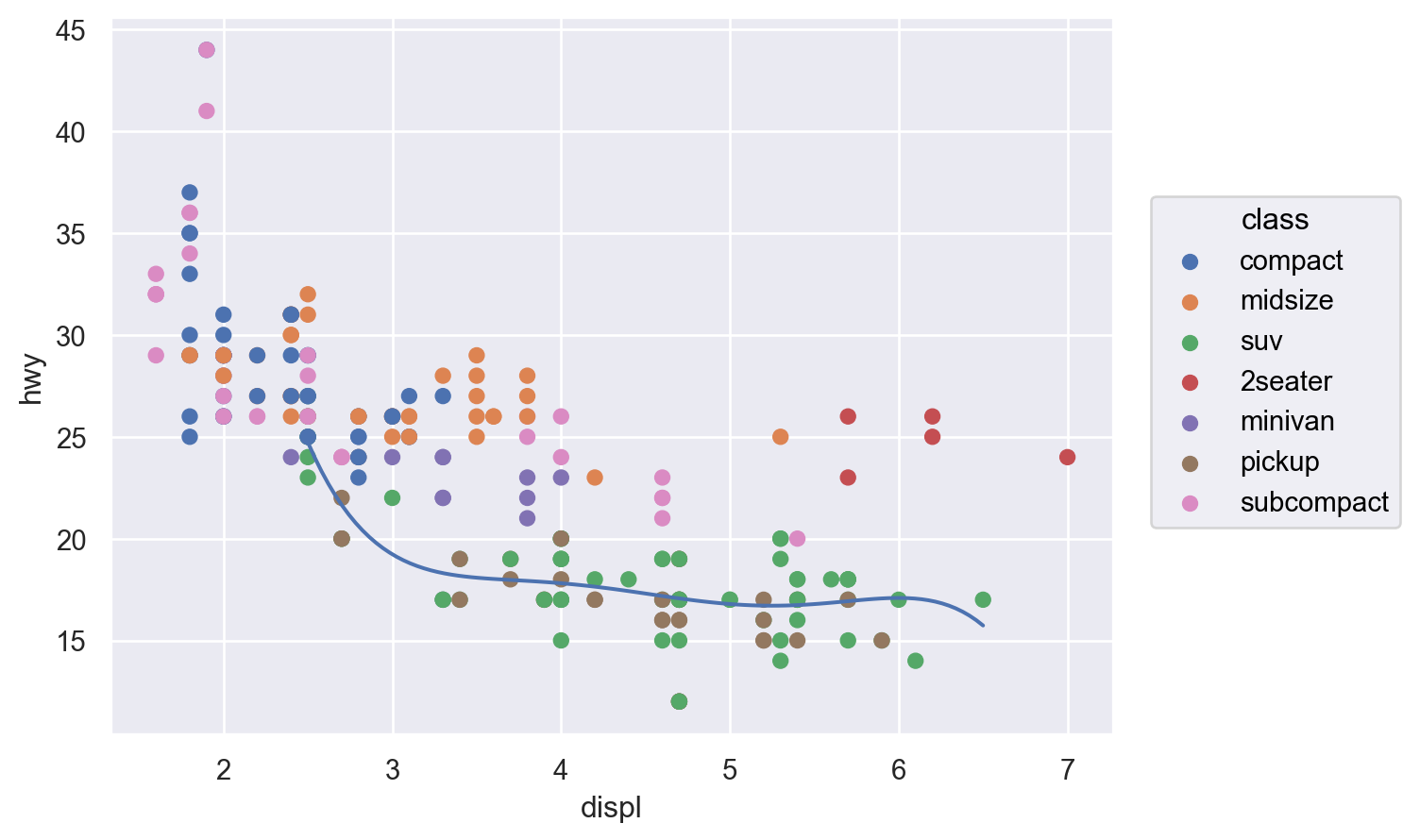
Q: 엔진의 크기(displ)와 연비(hwy)는 어떤 관계에 있는가?
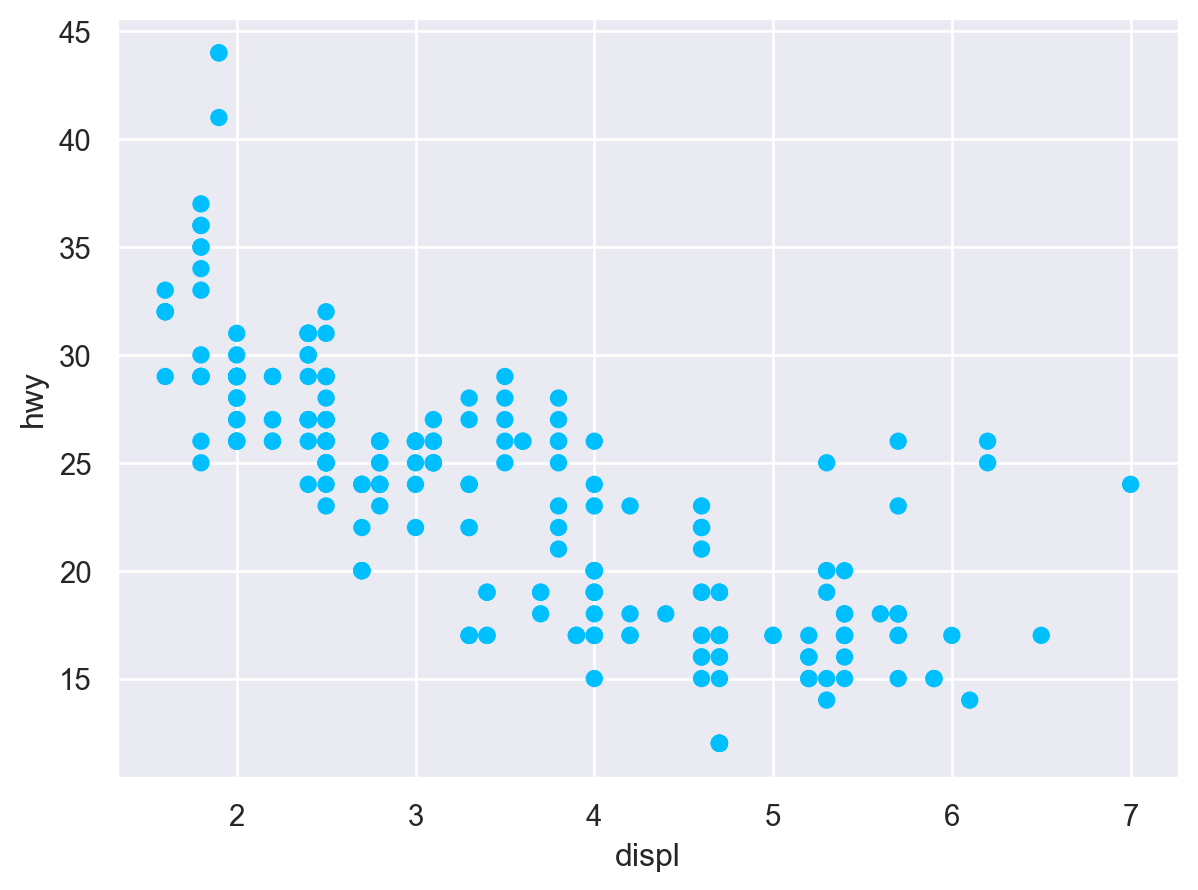
# Scatter plot: 산포도( so.Plot(mpg, x="displ", y="hwy") # empty plot을 생성하고, x, y축에 mapping할 mpg 데이터의 변수를 지정 .add(so.Dot()) # layer를 추가하여, points들을 Dot이라는 mark object를 써서 표현)
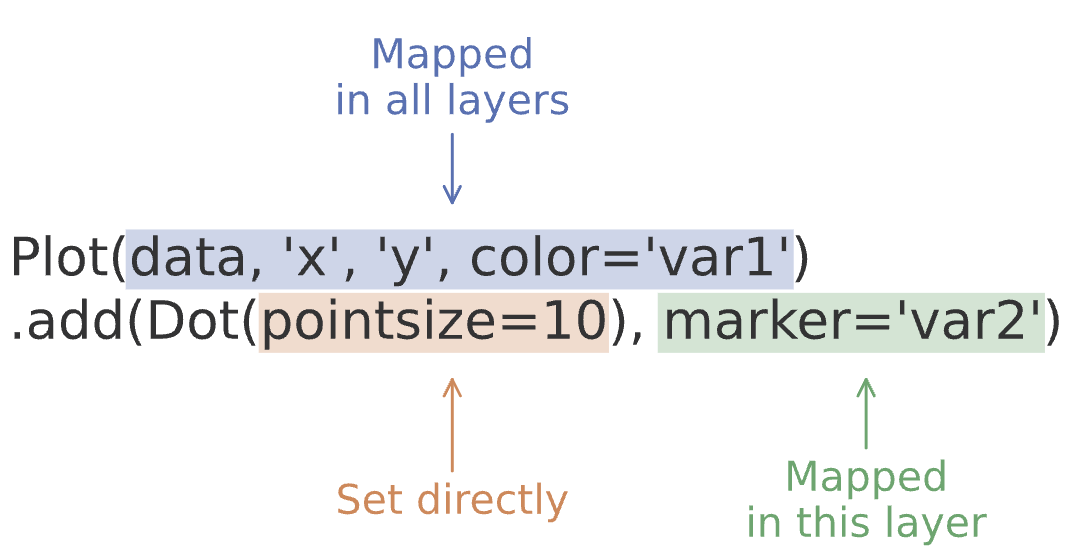
Layer-specific mappings
Global vs. local mapping
다음과 같이 첫번째 layer 안에서 x, y를 mapping하는 경우, 이후 새로 추가되는 layer에는 그 mapping이 적용되지 않음
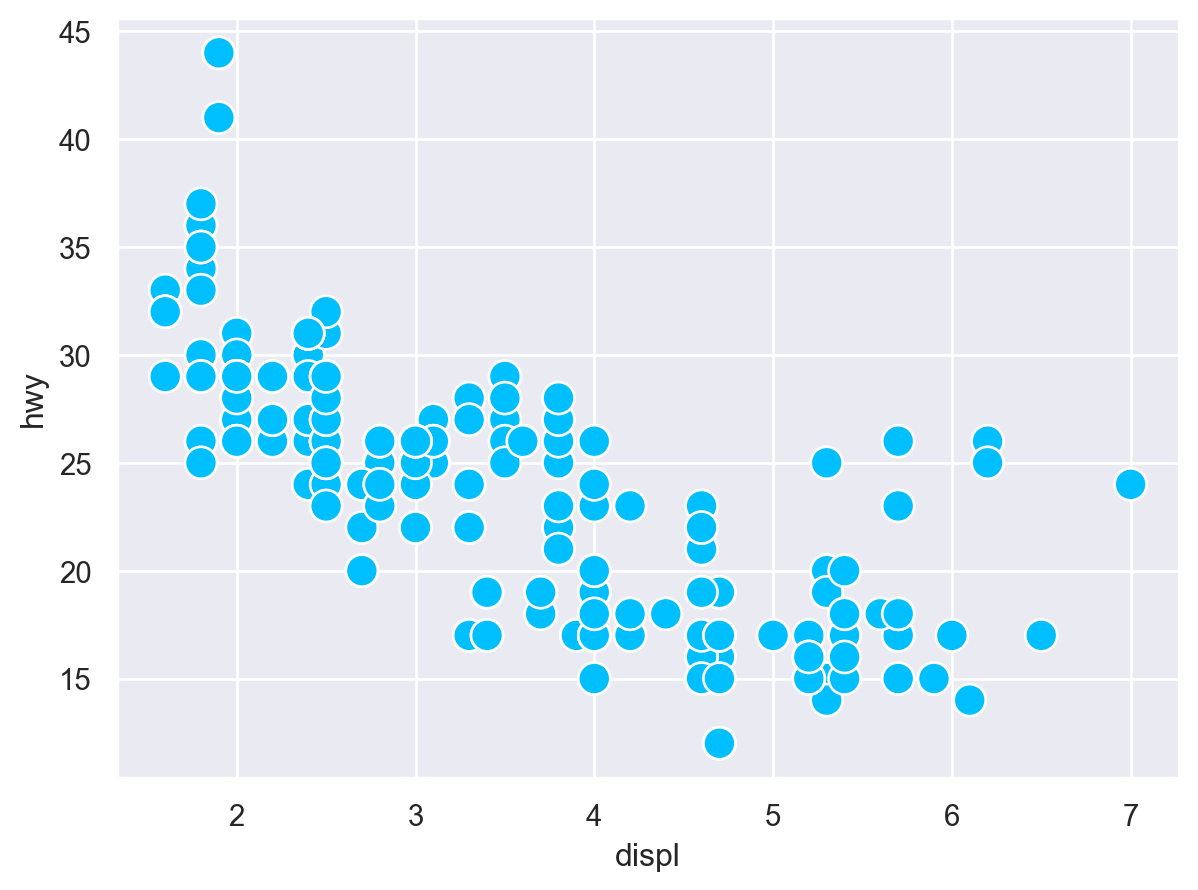
( so.Plot(mpg) .add(so.Dot(), x="displ", y="hwy") # 이 layer에서만 mapping이 유효)
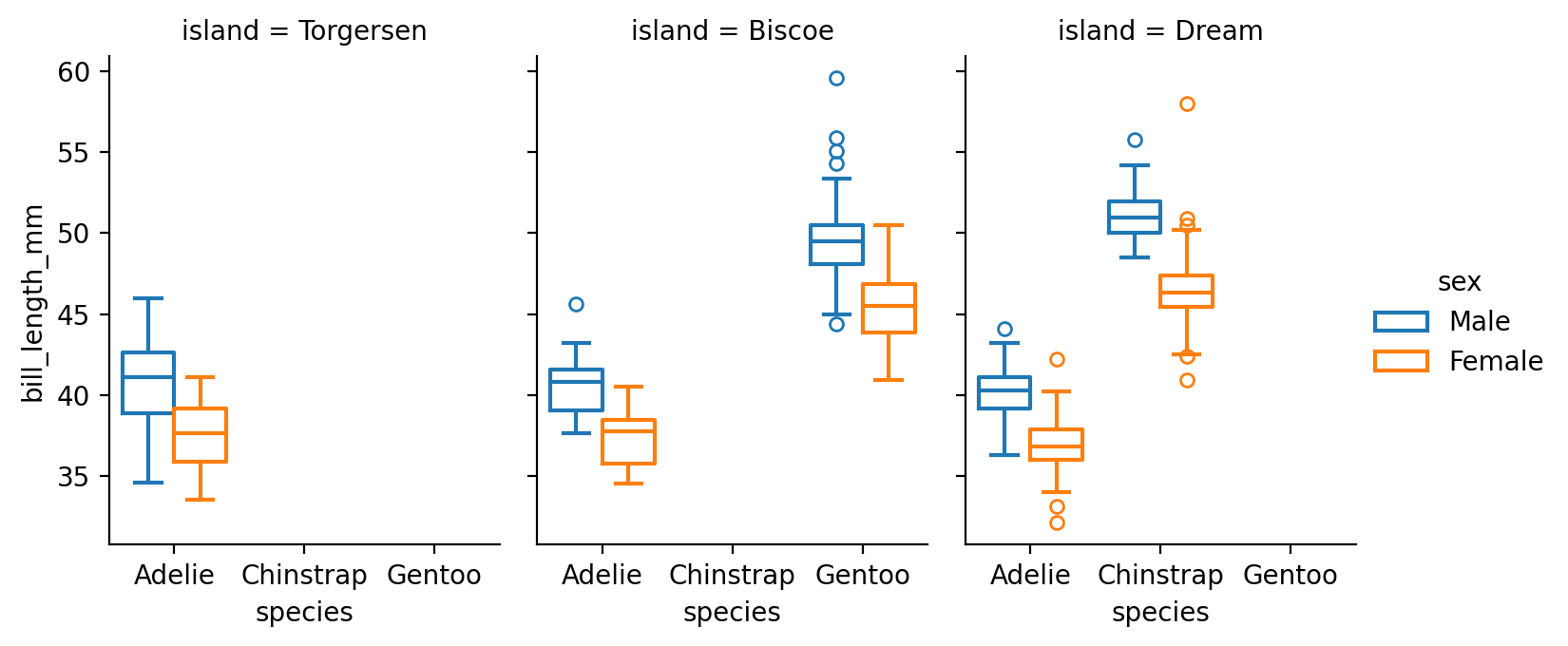
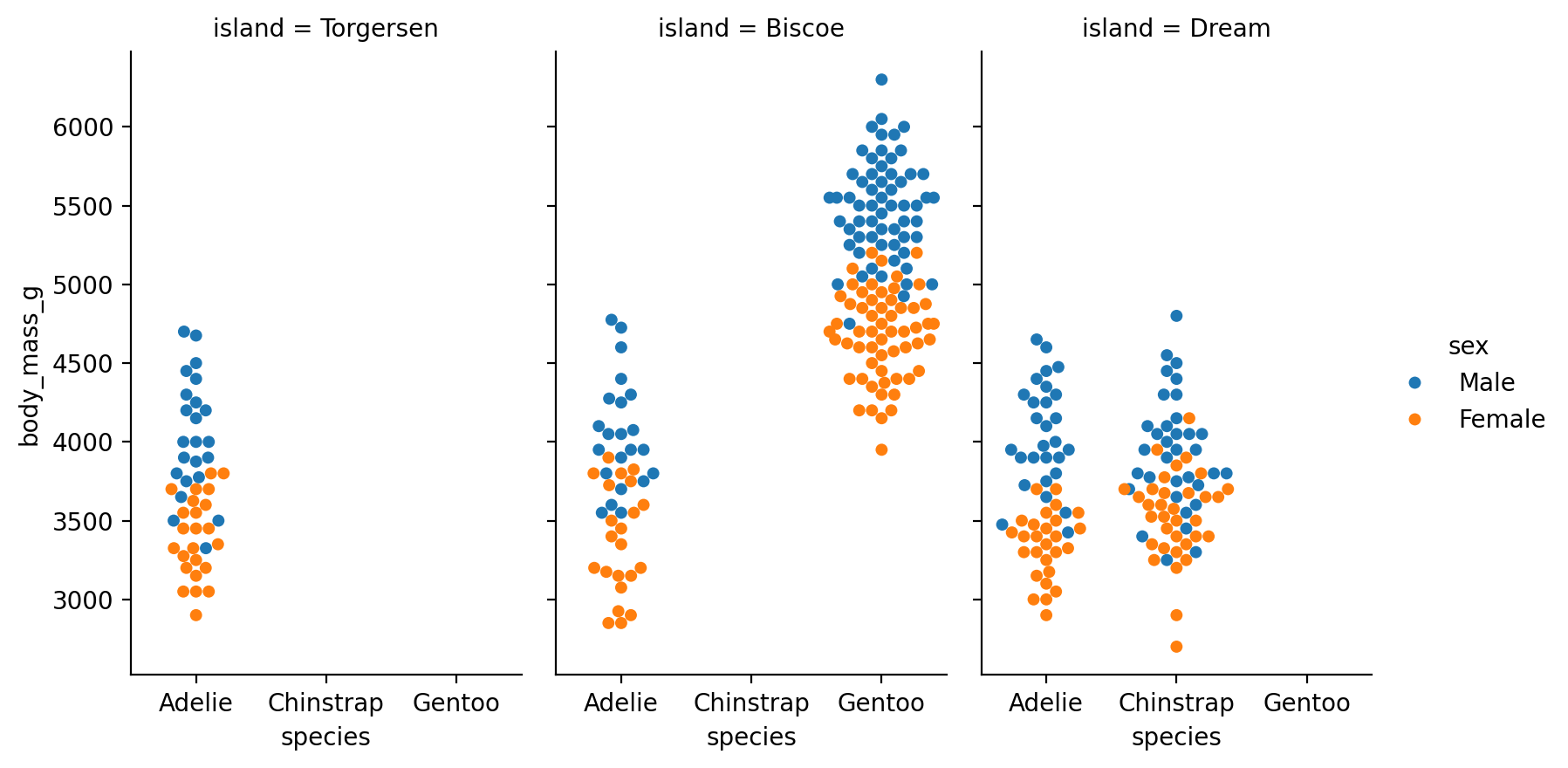
카테고리 변수인 경우
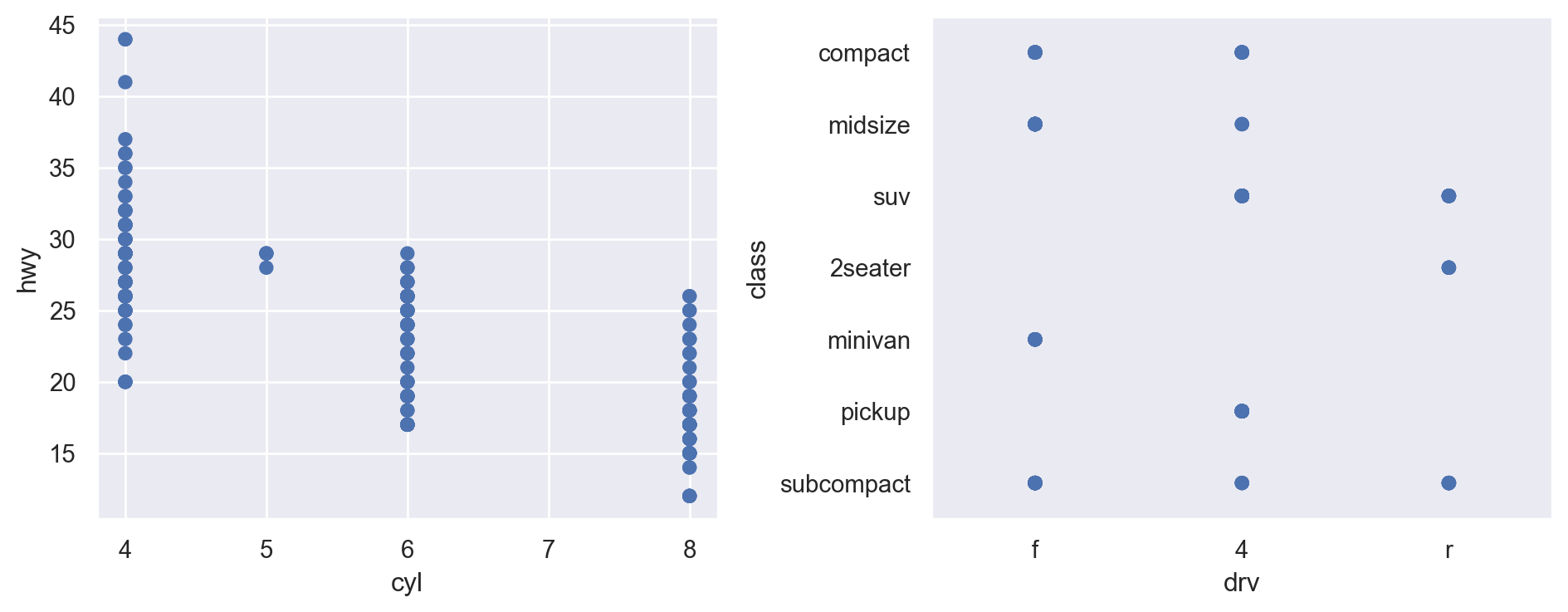
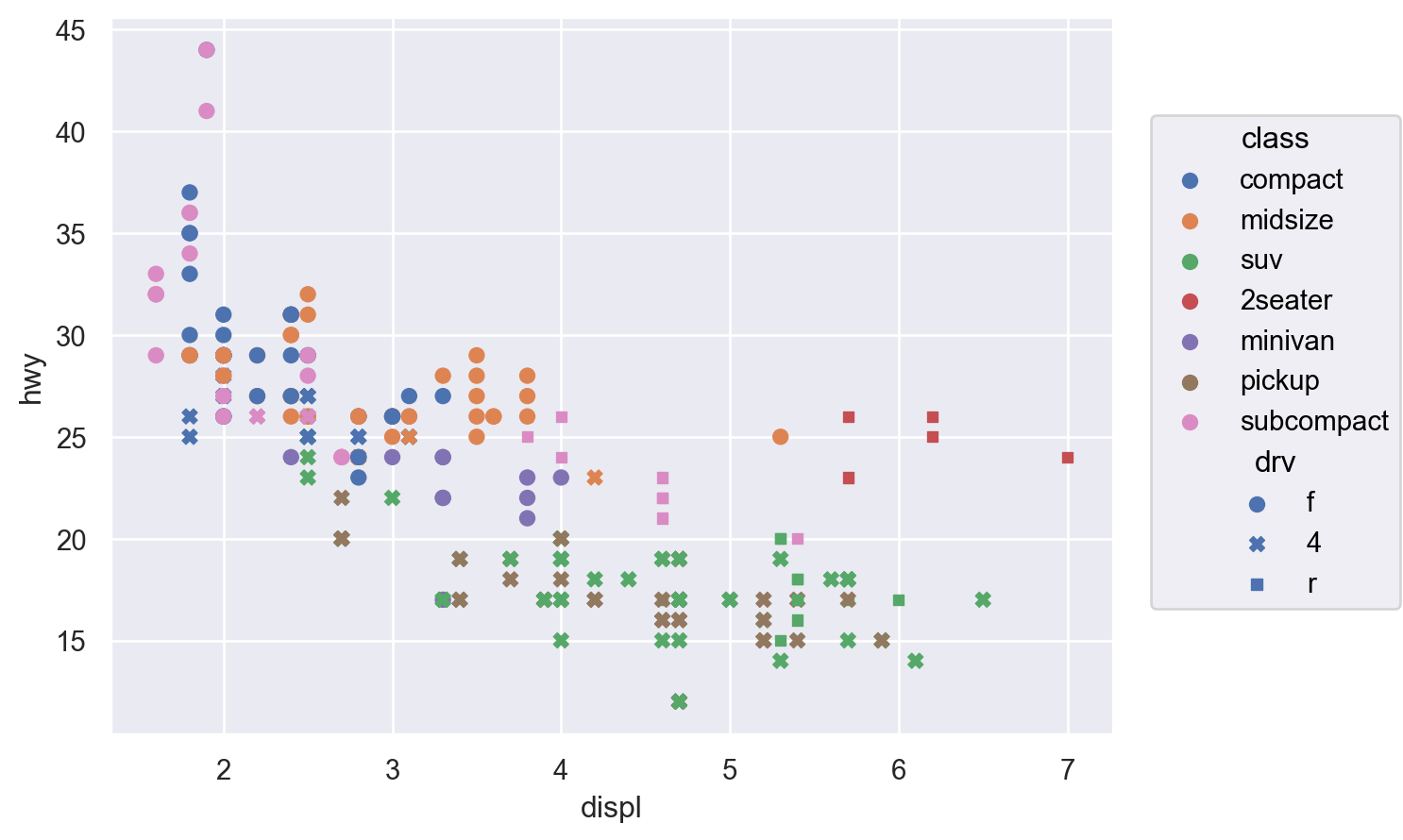
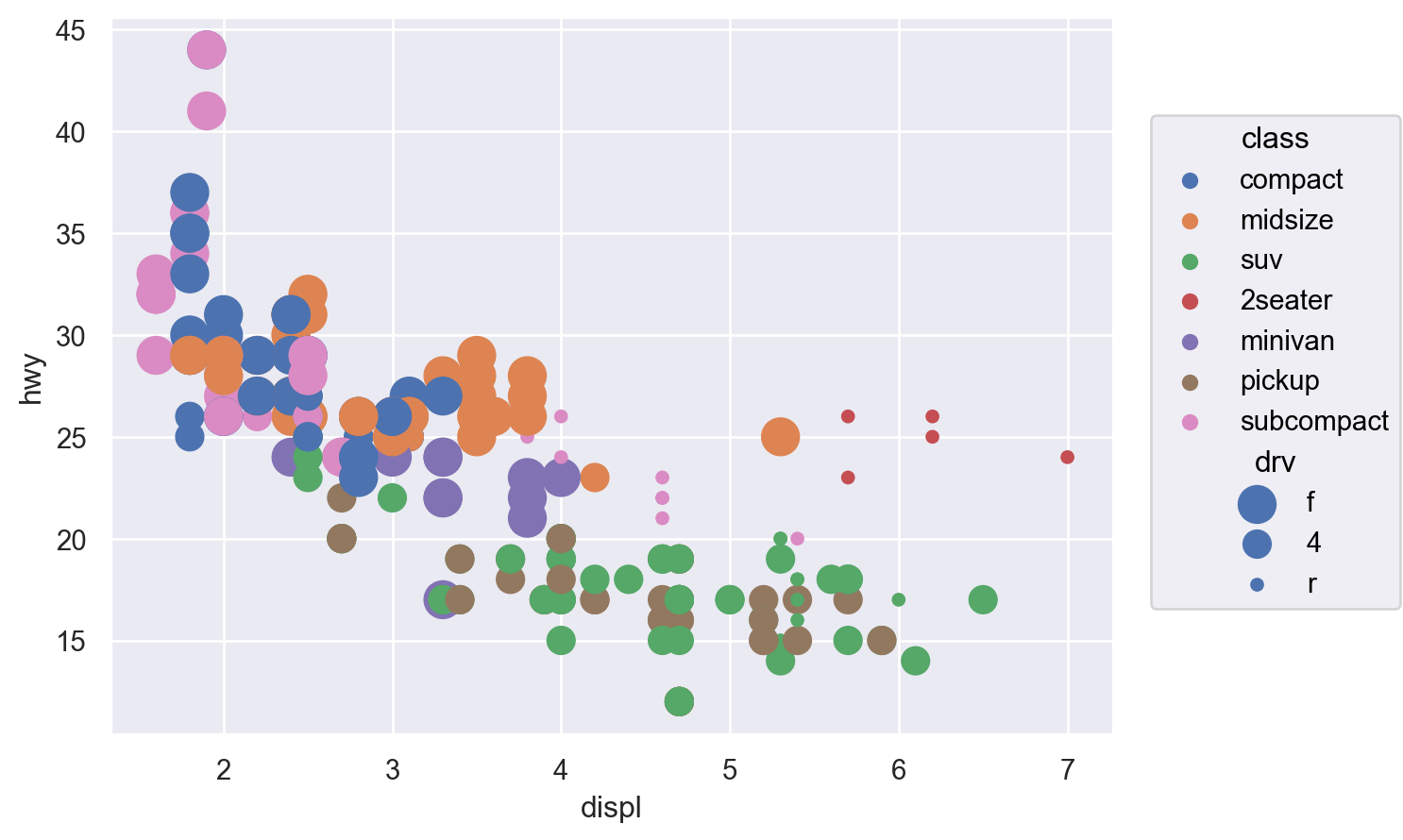
cyl (실린더 개수), hwy (고속도로 연비)의 관계를 scatterplot으로 살펴볼 수 있는가? (left)
class (차량 타입), drv (전륜 구동, 후륜 구동, 4륜 구동 타입)의 관계는 어떠한가? (right)
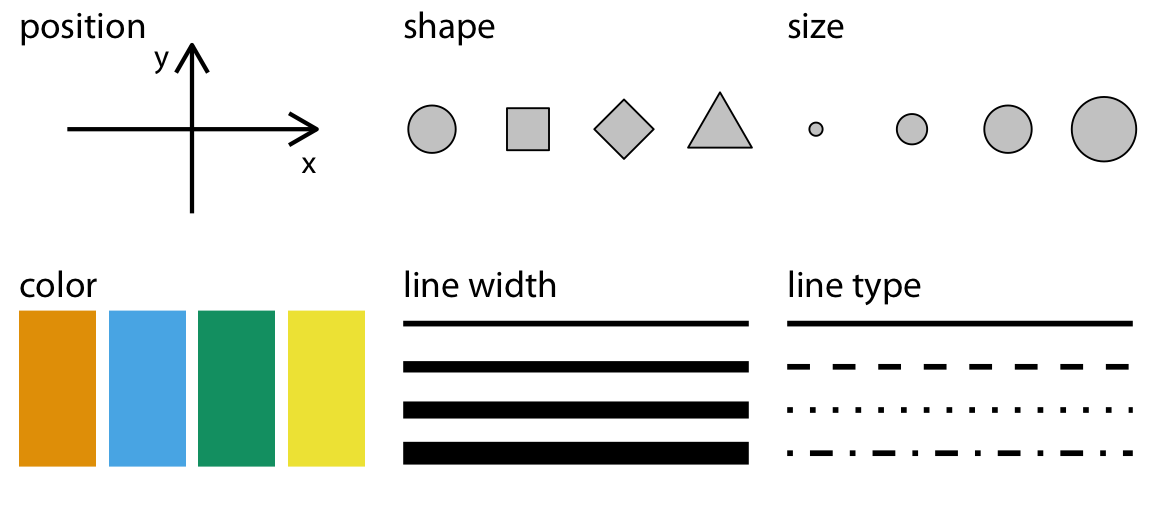
Aesthetic mappings
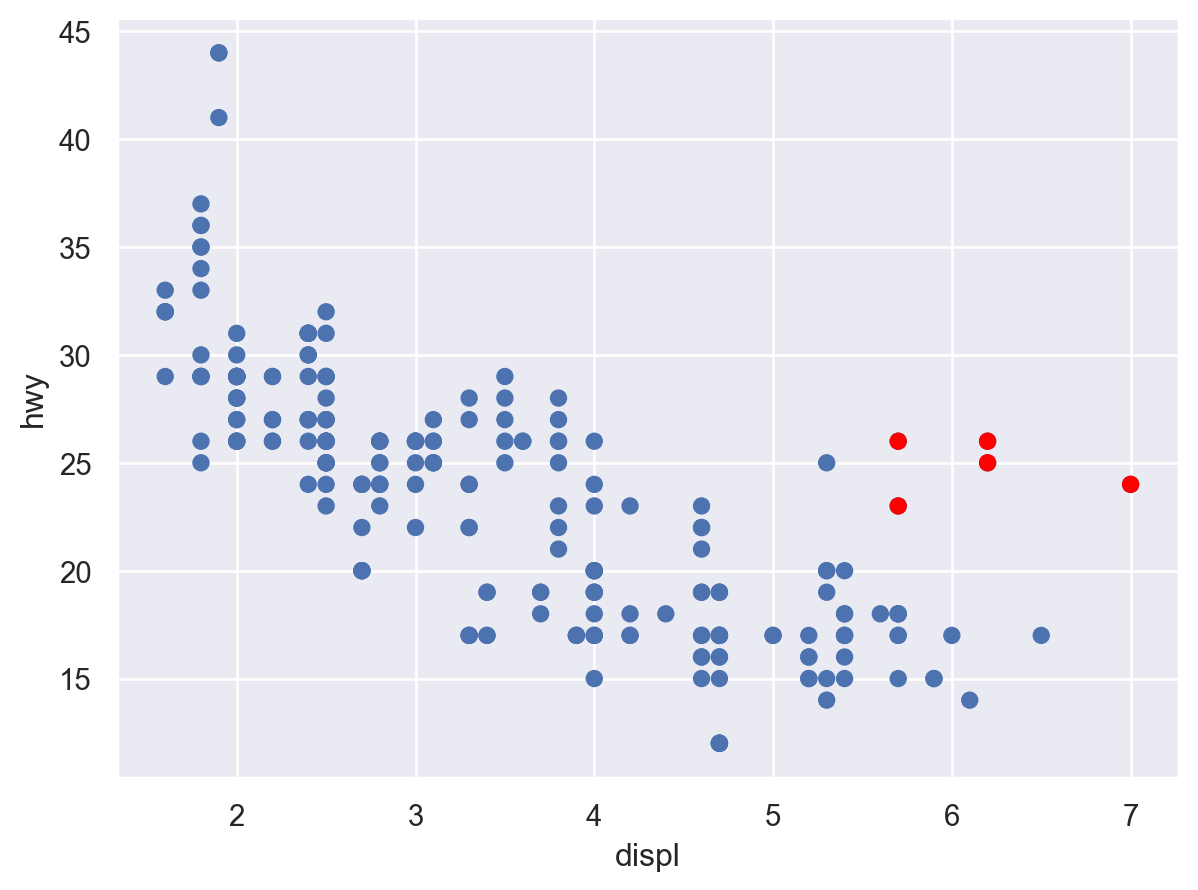
Q: 엔진의 크기와 연비와의 관계에서 보이는 트렌드 라인에서 심하게 벗어난 것이 있는가?
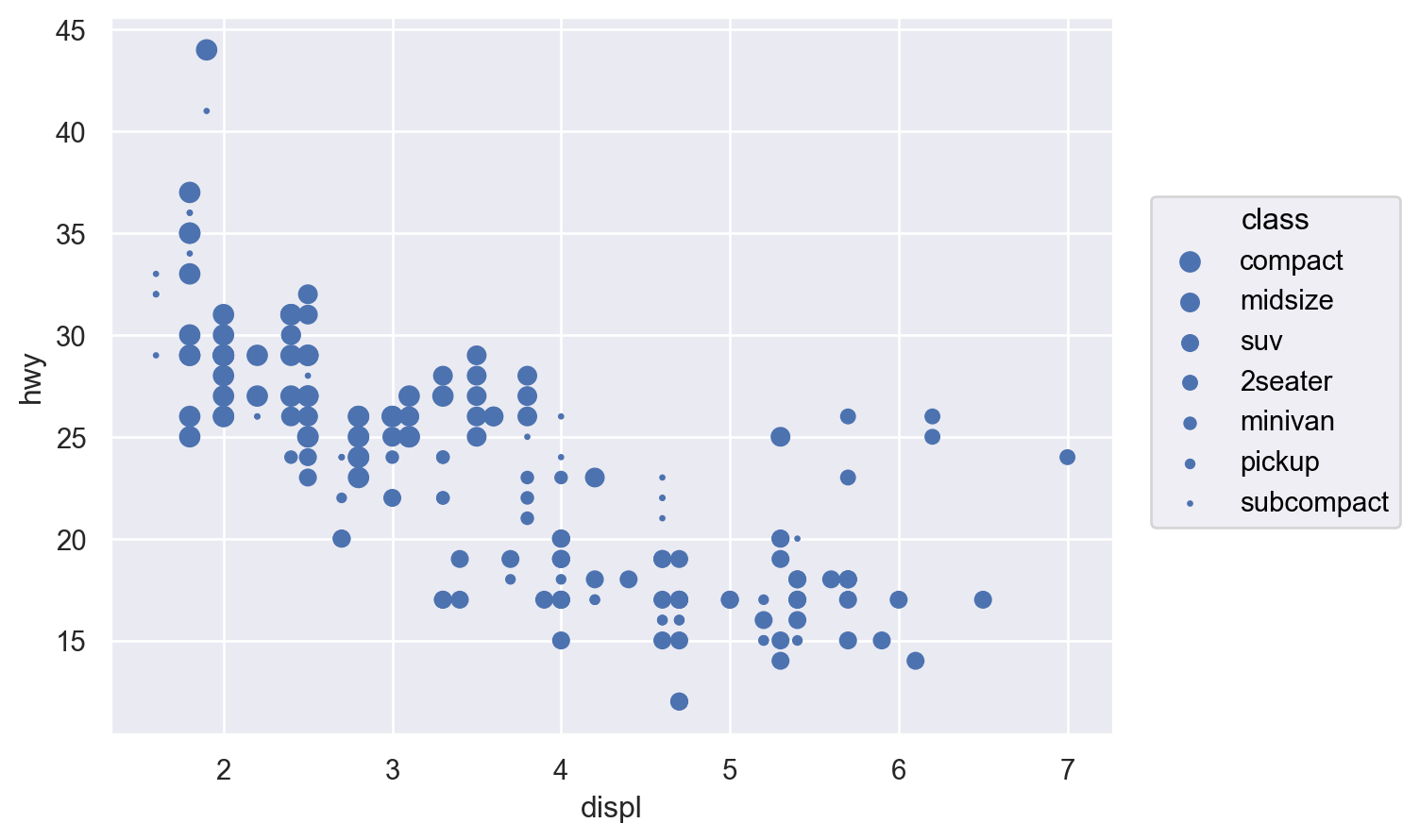
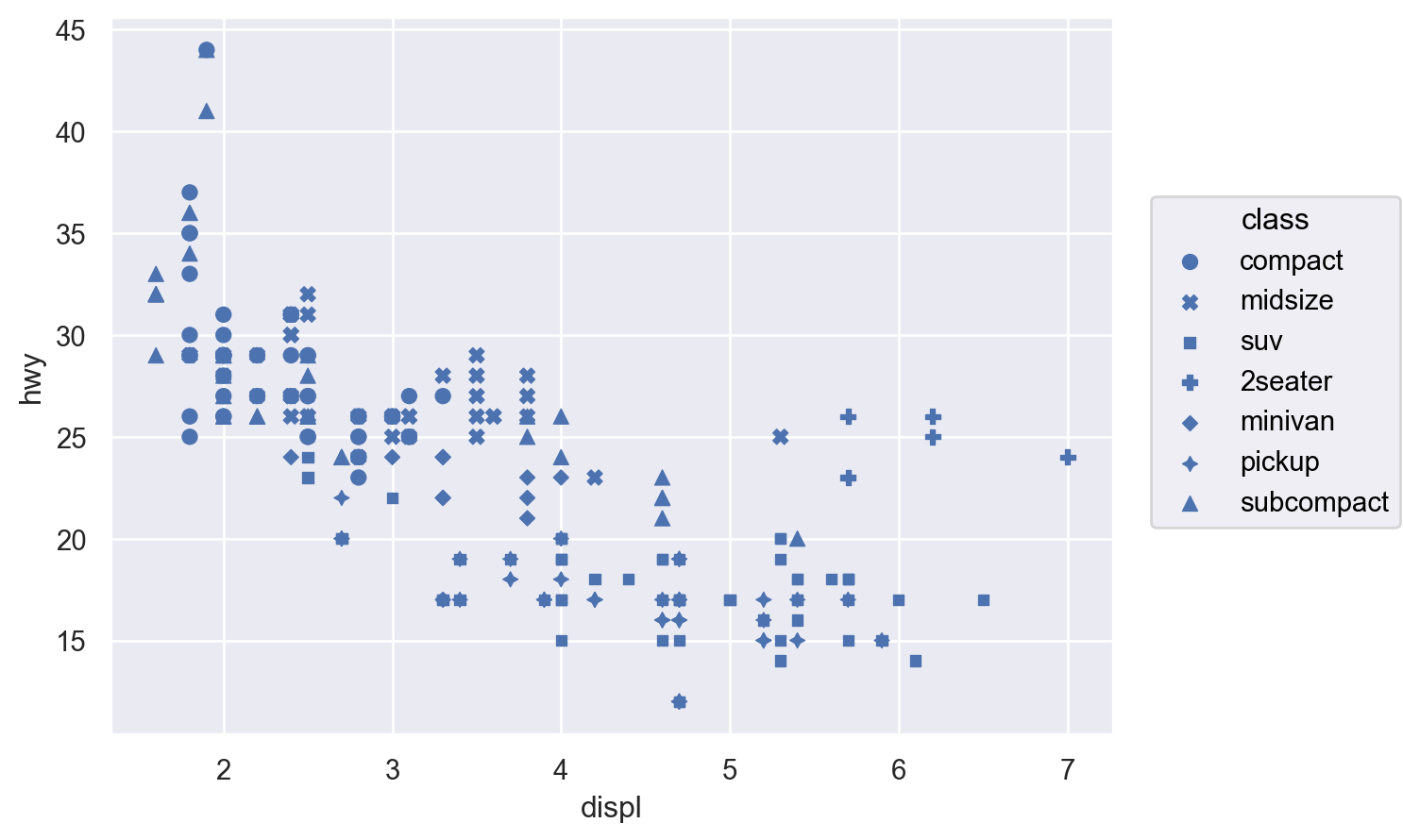
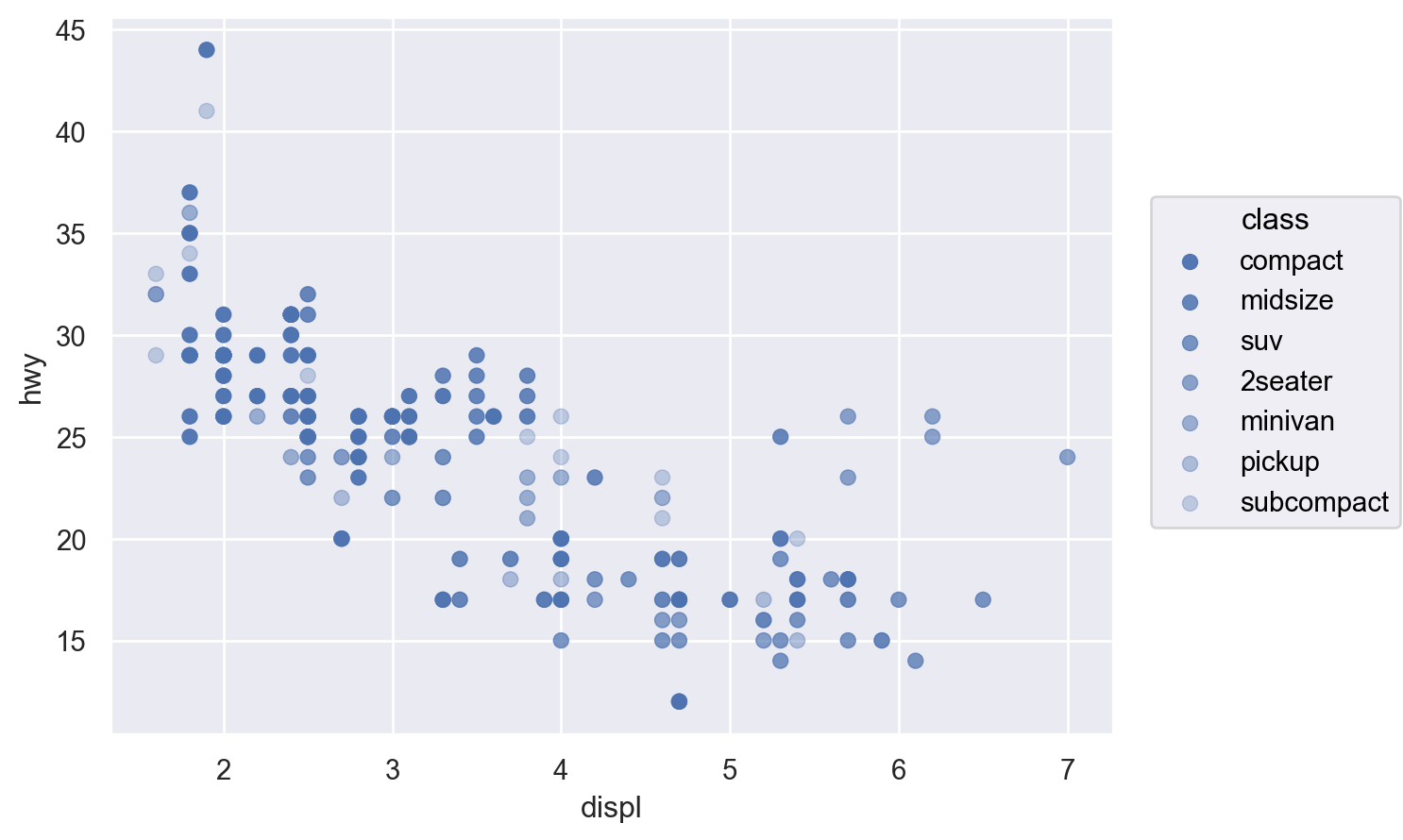
변수들을 x, y라는 position에 mapping하는 것에 추가하여 다음과 같은 속성(aesthetic)에 mapping할 수 있음
색(color), 크기(pointsize), 모양(marker), 선 종류(linestyle), 투명도(alpha)
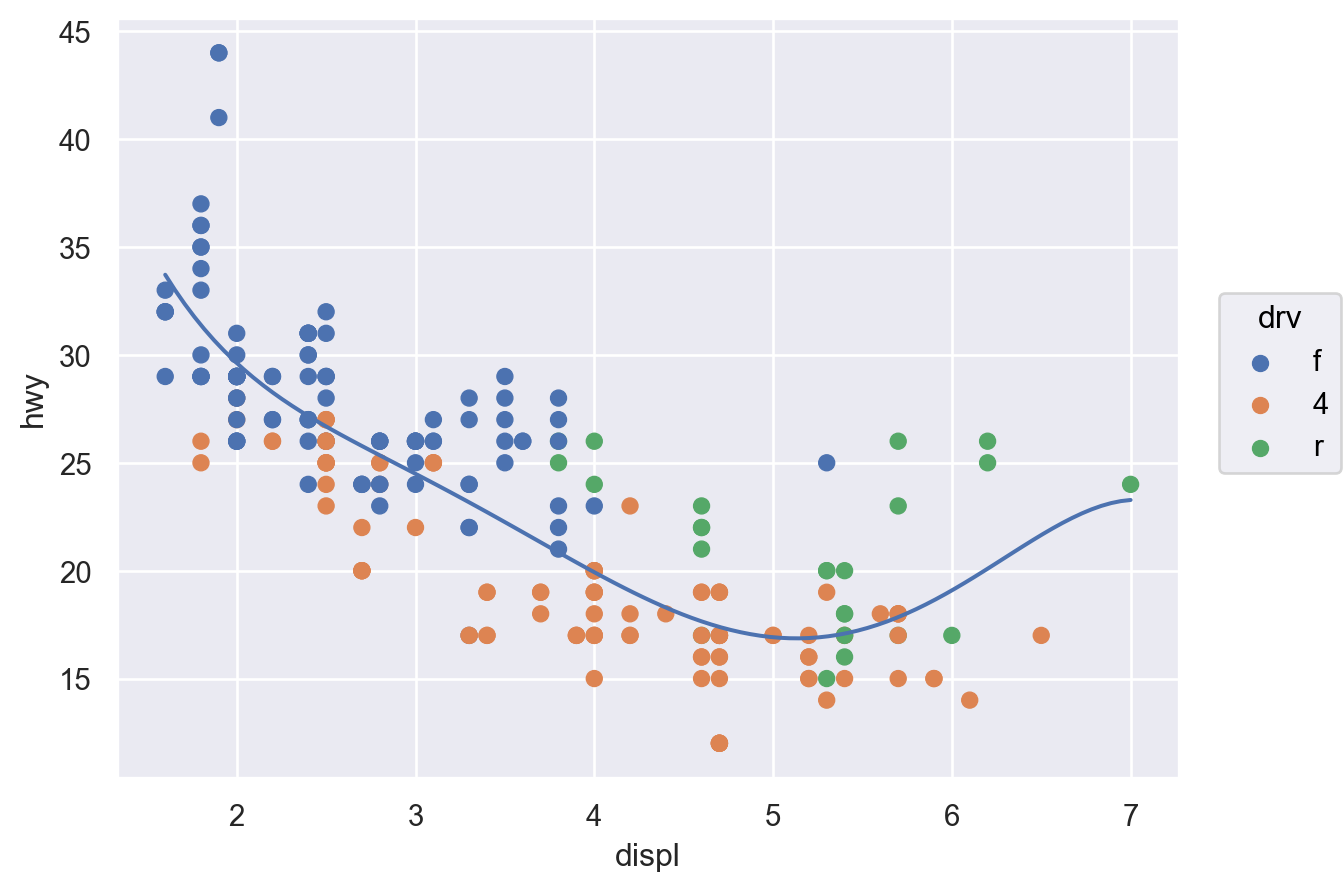
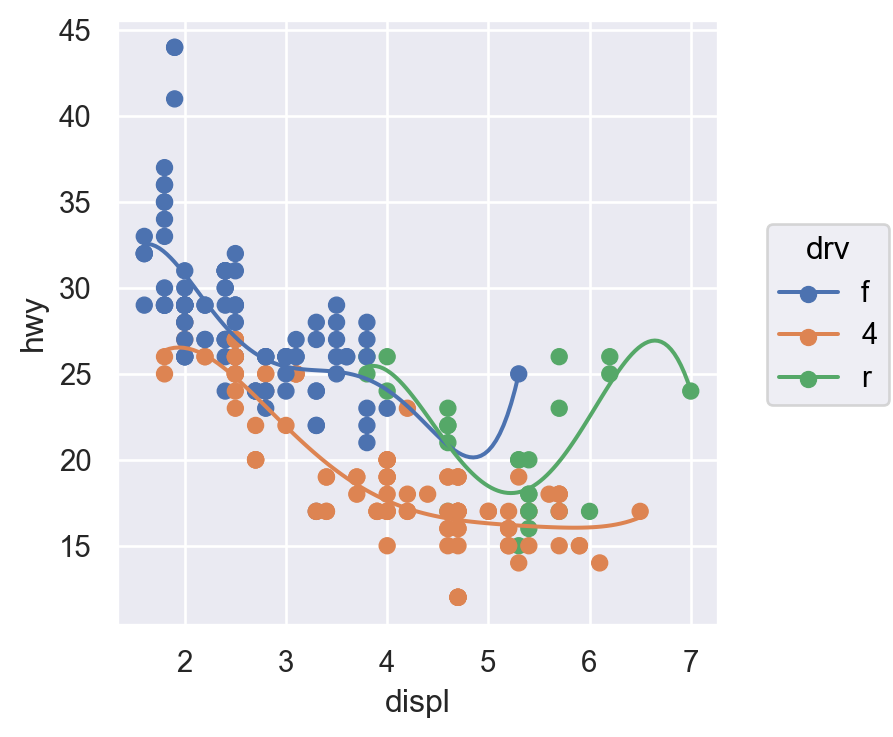
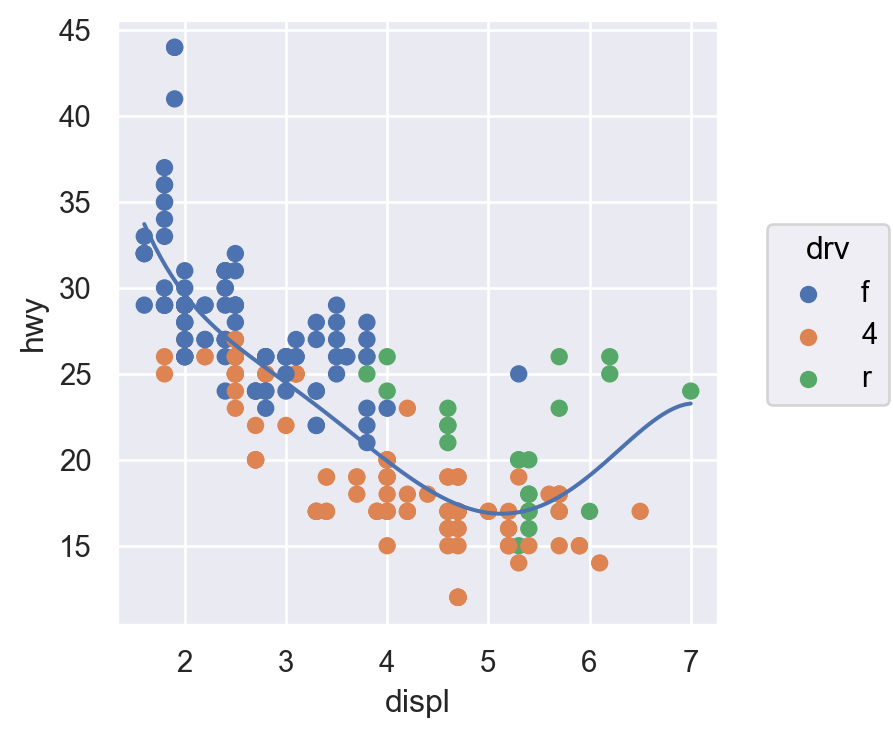
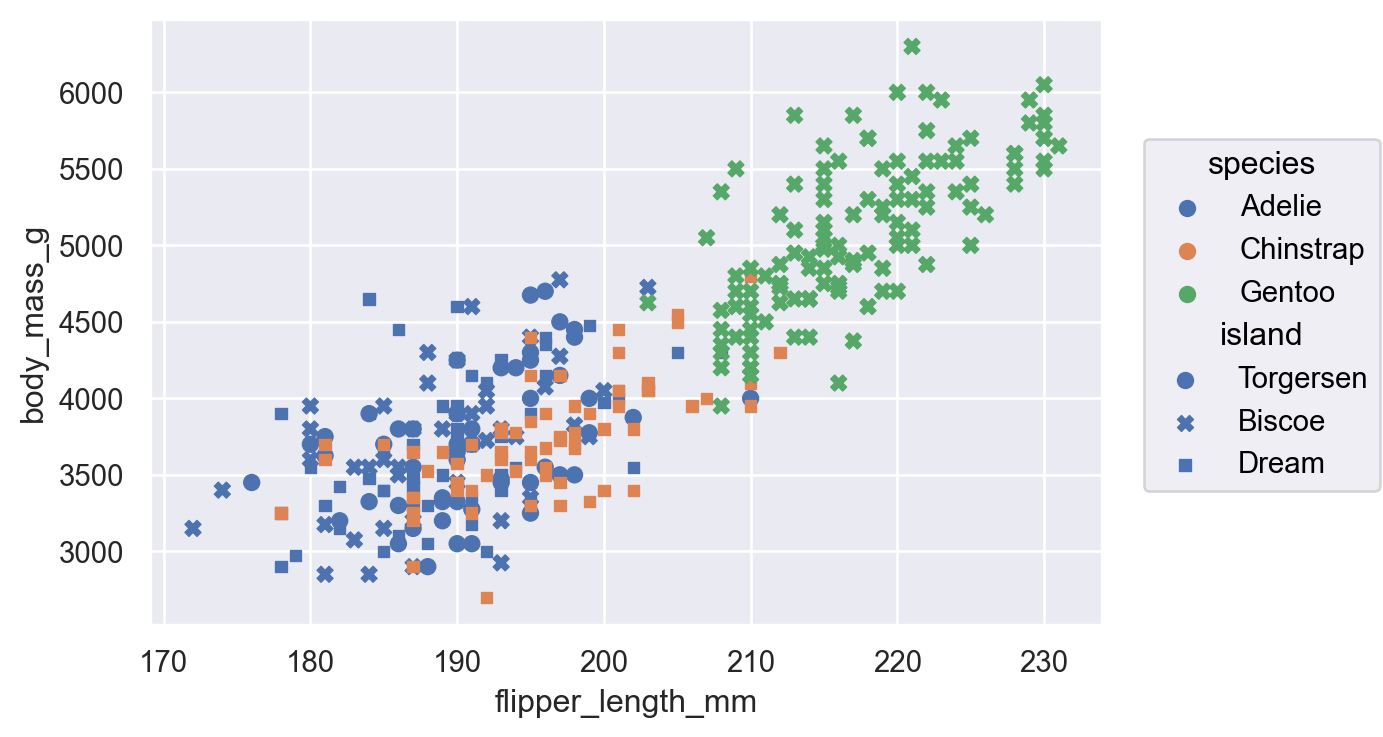
( so.Plot(mpg, x="displ", y="hwy", color="drv") # color mapping이 이후 모든 layer에 적용 .add(so.Dot()) .add(so.Line(), so.PolyFit(5)))( so.Plot(mpg, x="displ", y="hwy") .add(so.Dot(), color="drv") # color mapping이 이 layer에만 적용 .add(so.Line(), so.PolyFit(5)))
(a) color가 모든 layers에 적용: global mapping
(b) color가 두번째 layer에만 적용: local mapping
Figure 2: Inherited mapping
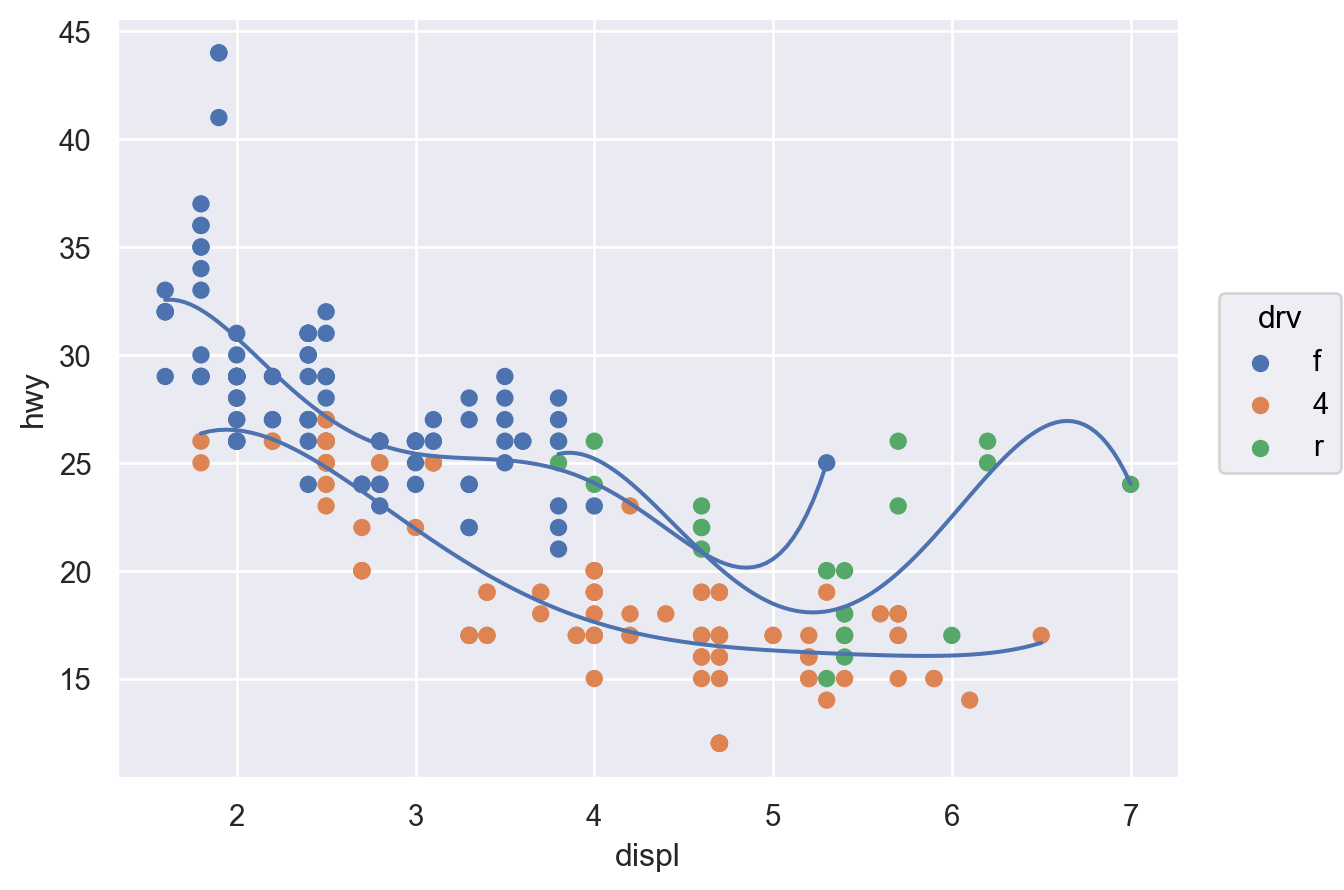
( so.Plot(mpg, x="displ", y="hwy") .add(so.Dot(), color="drv") .add(so.Line(), so.PolyFit(5), group="drv") # color가 아닌 group으로 grouping)# 다항함수 fit의 특징 및 주의점
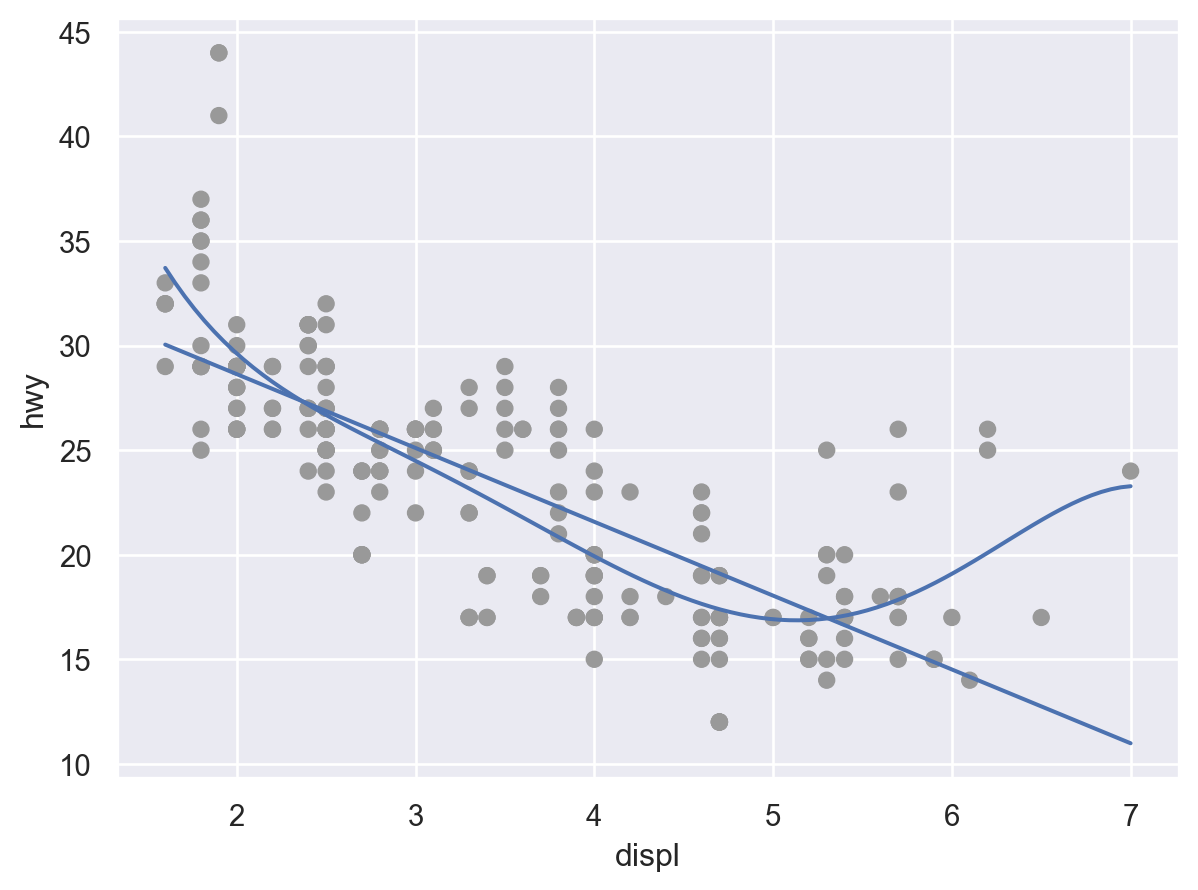
Linear fit vs. smoothing fit:
선형적인 트렌드에서 얼마나 벗어나는가?
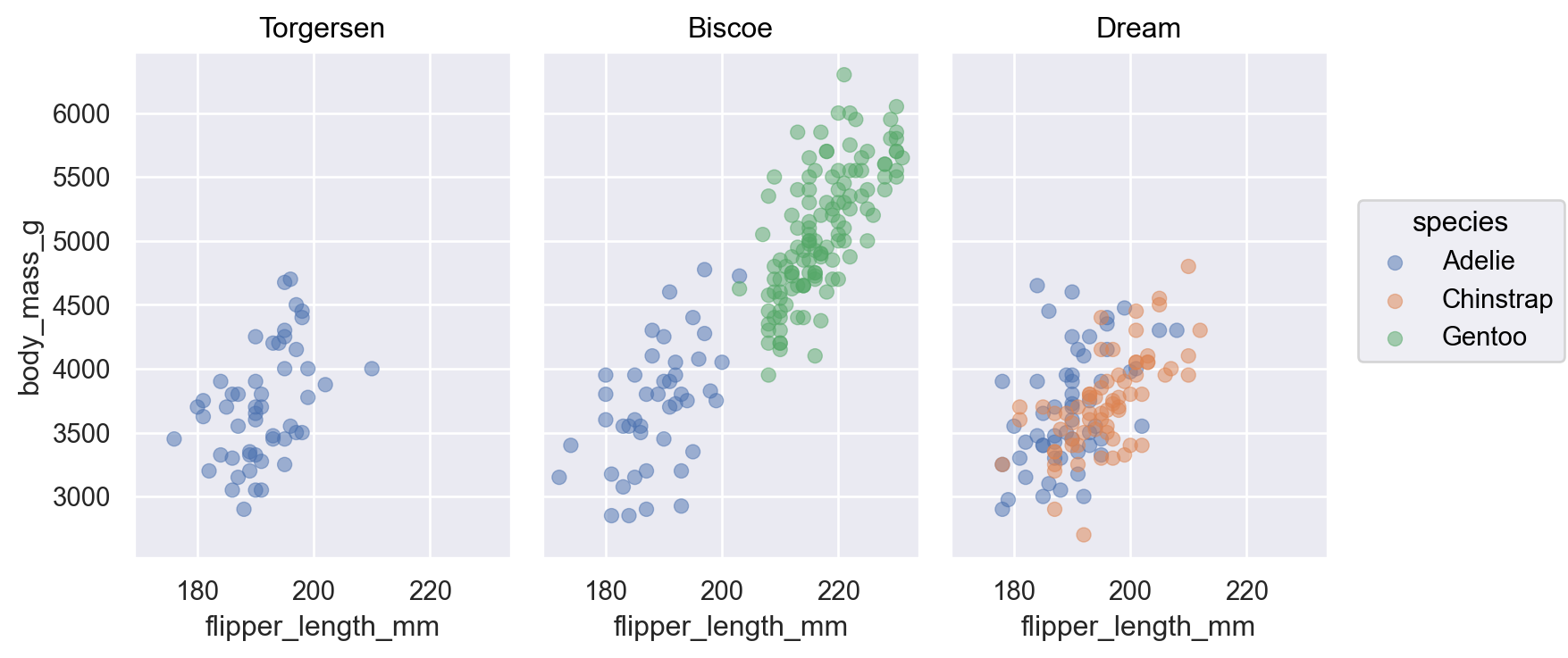
( so.Plot(df, x=, y=, color=, ...) # global mapping .add(so.Dot(color=, pointsize=,...)) # mark object + setting properties .add(so.Line(), x=, y=, color=, ...) # local mapping .add(so.Line(), so.Polyfit(5)) # 통계적으로 변환한 값을 Line plot으로 표현 .add(so.Bar(), so.Hist(stat="proportion")) # 통계적으로 변환한 값을 Bar plot로 표현 ... .facet(col=, row=, wrap=) # 카테고리의 levels에 따라 나누어 표현)
Aesthetic mapping
위치(position): x축, y축
색(color), 크기(pointsize), 모양(marker), 선 종류(linestyle), 투명도(alpha)
global vs. local mapping
Geometric objects
Dot marks: Dot, Dots
Line marks: Line, Path, Dash, Range
Bar marks: Bar, Bars
Fill marks: Area, Band
Text marks: Text
Setting properties
Marks (.Dot(), .Line(), .Bar(), …) 내부에 속성을 지정하고, marks마다 설정할 수 있는 속성이 다름.
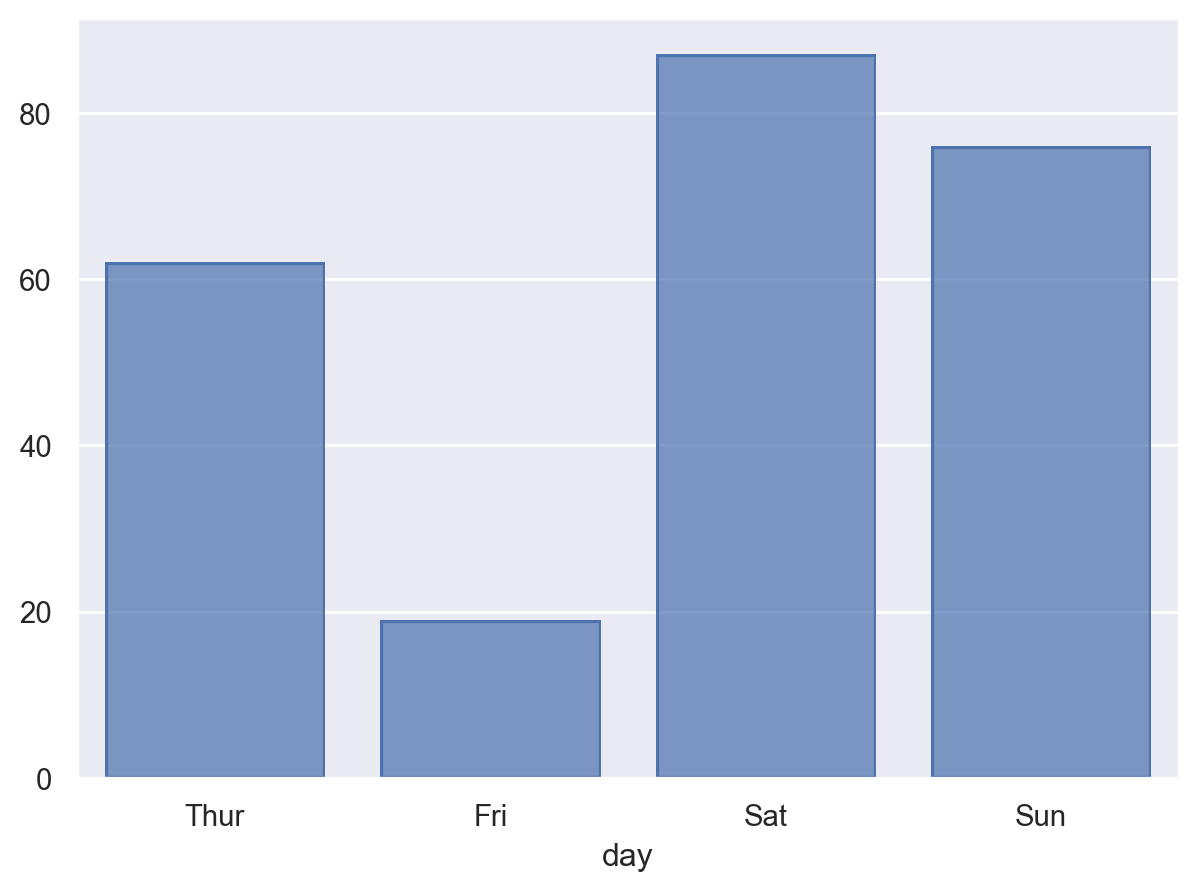
( so.Plot(tips, x="day") .add(so.Bar(), so.Count()) # category type의 변수는 순서가 존재. # 그렇지 않은 경우 알바벳 순서로. )
Note
복잡한 통계치의 경우 직접 구한후 plot을 그리는 것이 용이
count_day = tips.value_counts("day", normalize=True).reset_index(name="pct")# day pct# 0 Sat 0.36# 1 Sun 0.31# 2 Thur 0.25# 3 Fri 0.08( so.Plot(count_day, x="day", y="pct") .add(so.Bar()))
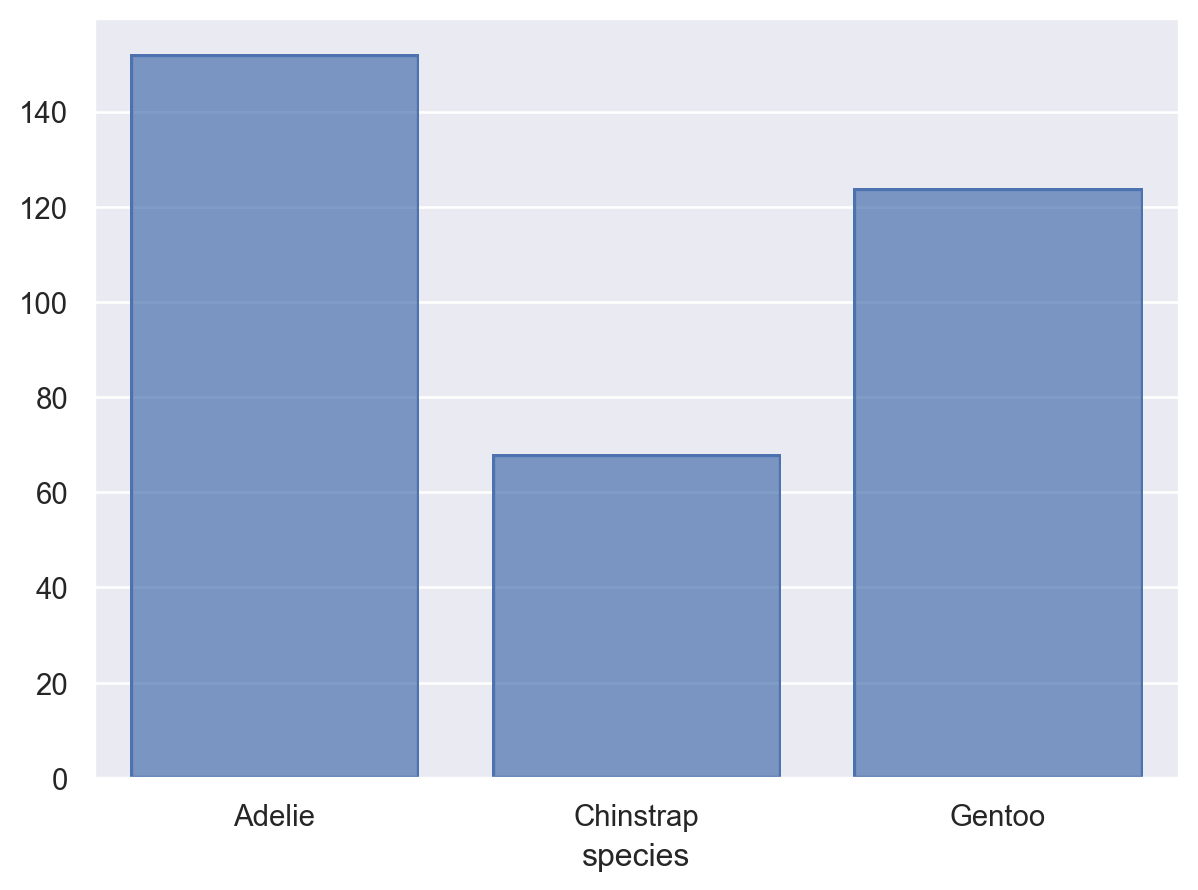
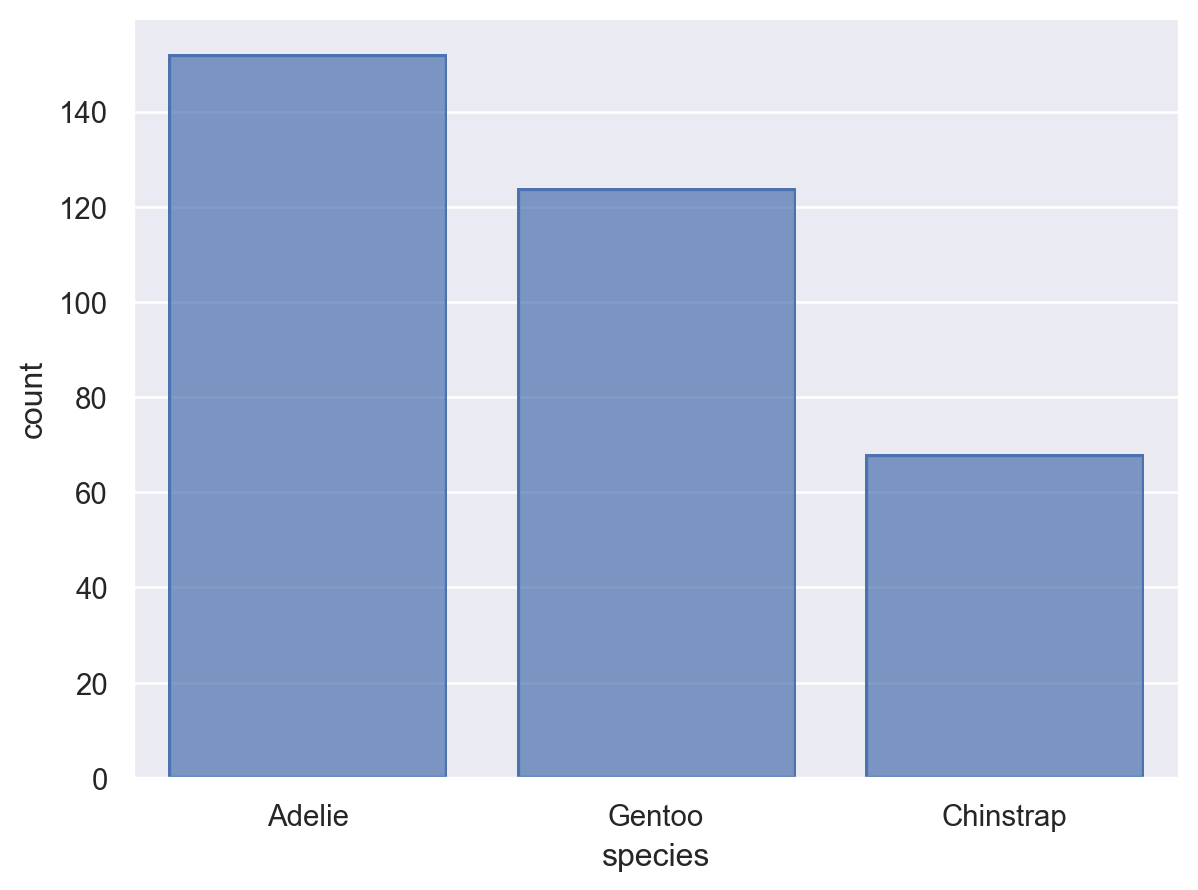
penguins = sns.load_dataset("penguins") # load a dataset: penguins# Species에 inherent order가 없음; 알파벳 순으로 정렬( so.Plot(penguins, x="species") .add(so.Bar(), so.Count()))
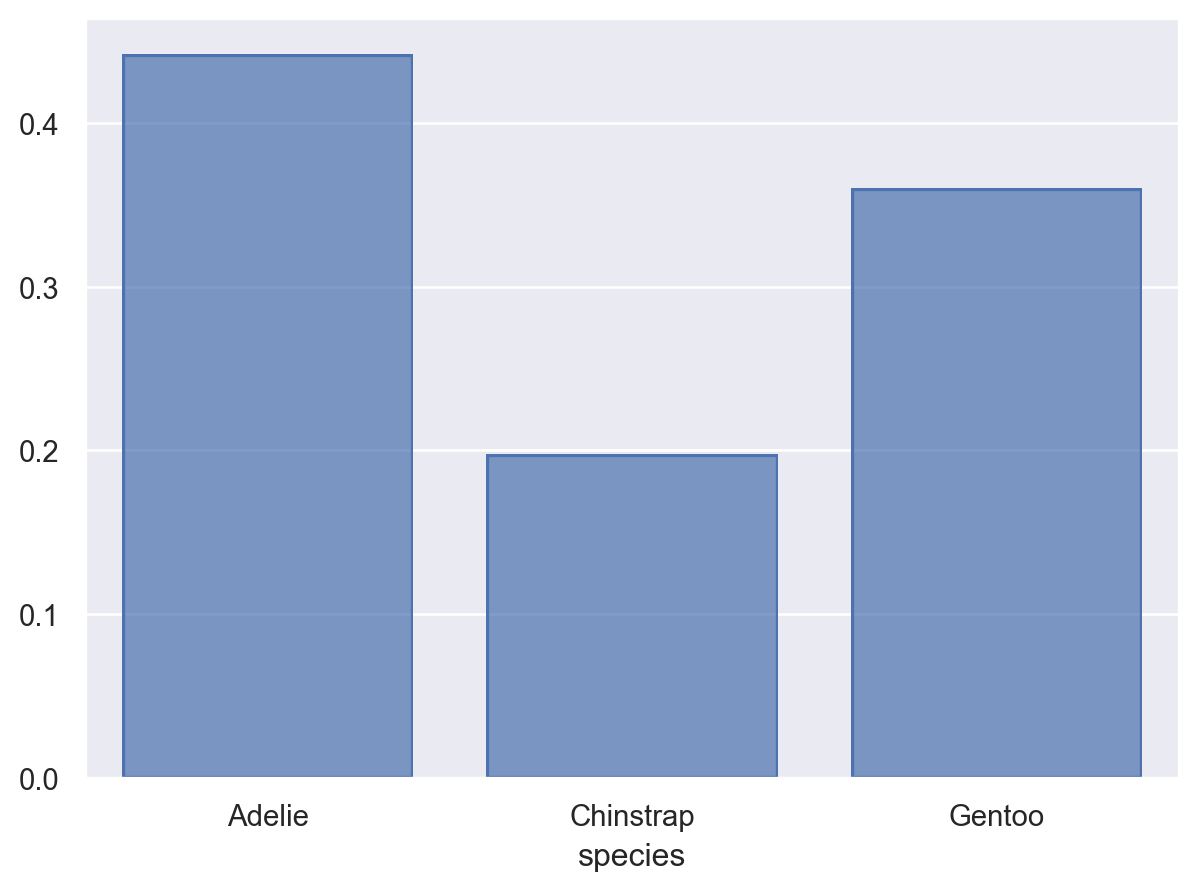
( so.Plot(penguins, x="species") .add(so.Bar(), so.Hist("proportion")) # Hist()의 default는 stat="count")# grouping의 처리에 대해서는 뒤에... 에를 들어, color="sex"
Important
표시 순서를 변경하는 일은 의미있는 플랏을 만드는데 중요
나중에 좀 더 자세히 다룸
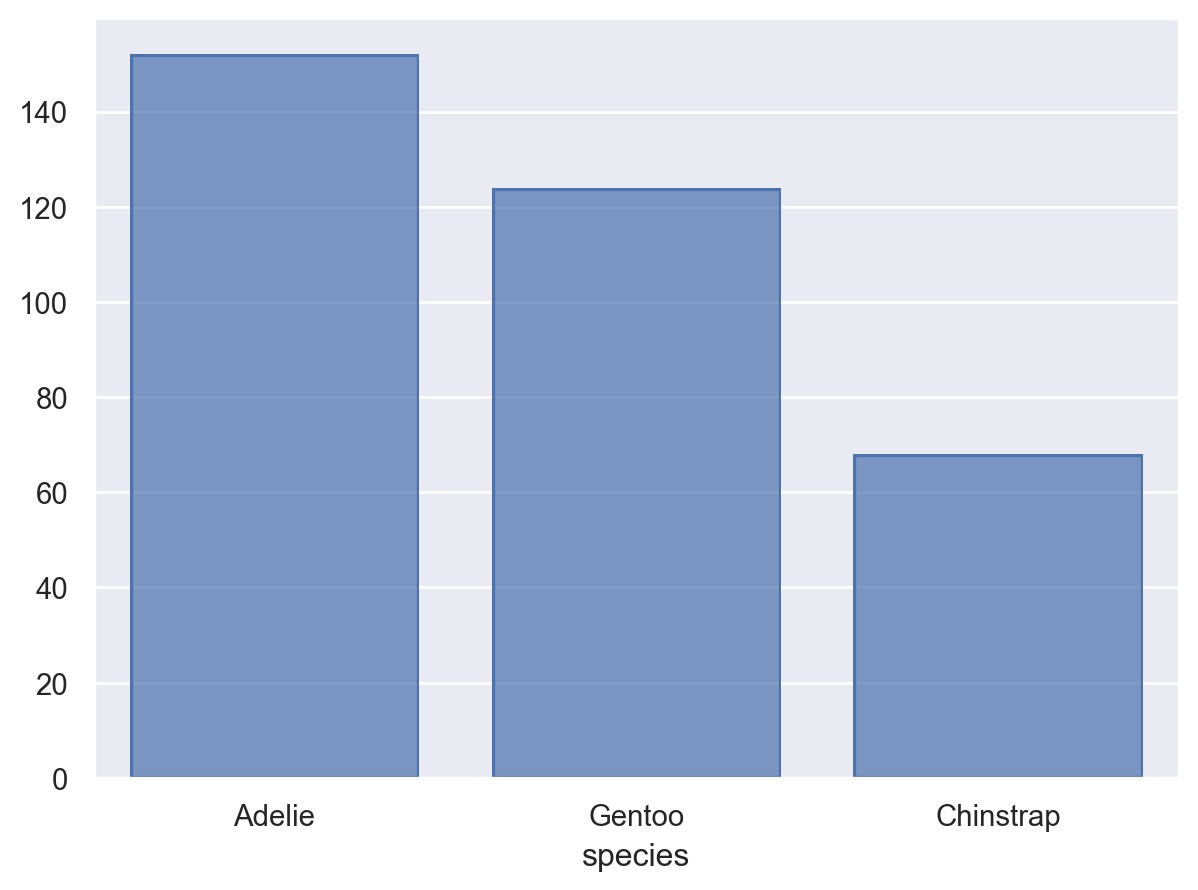
# value_counts()는 크기대로 sorting!reorder = penguins.value_counts("species").index.values#> array(['Adelie', 'Gentoo', 'Chinstrap'], dtype=object)( so.Plot(penguins, x="species") .add(so.Bar(), so.Count()) .scale(x=so.Nominal(order=reorder)) # x축의 카테고리 순서를 변경)# 직접 개수를 구해 그리는 경우, 테이블의 순서대로 그려짐( so.Plot(penguins.value_counts("species").reset_index(), x="species", y="count") .add(so.Bar()))
A numerical variable
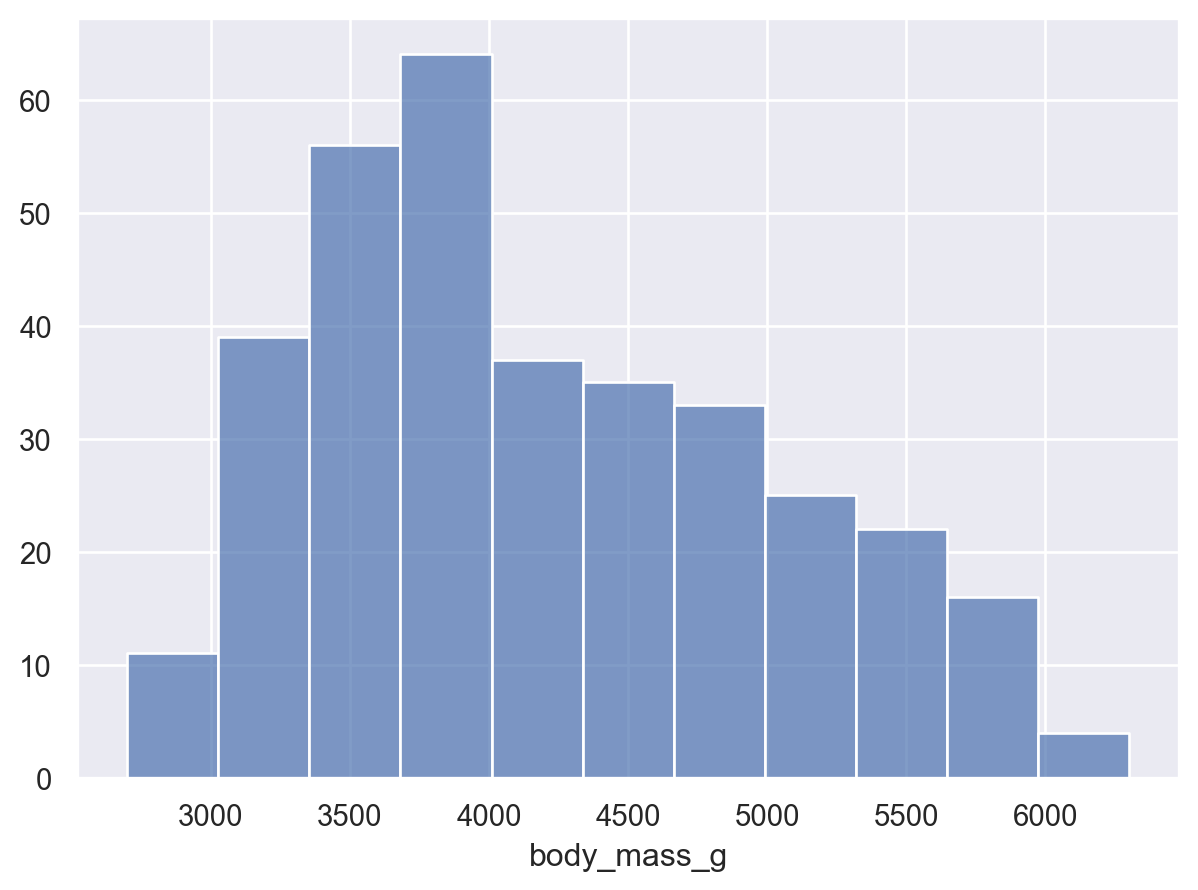
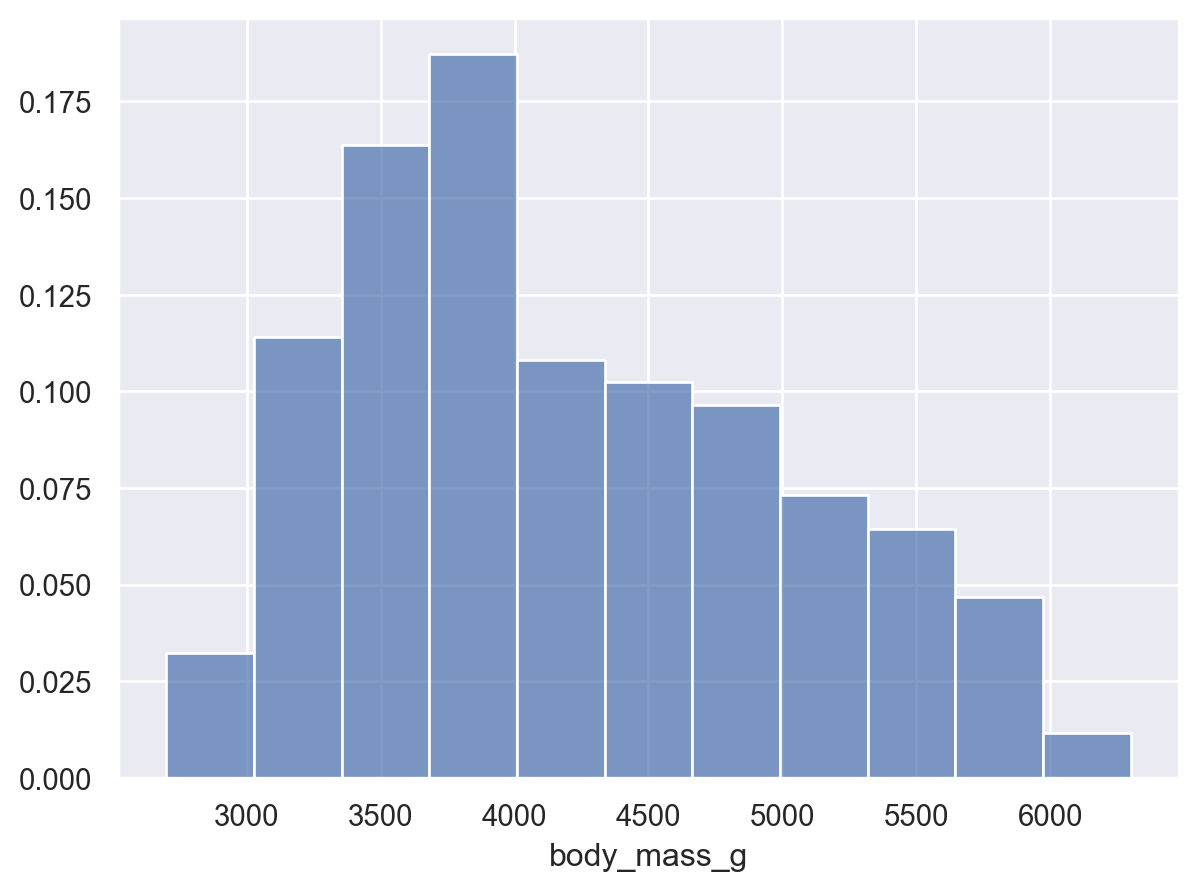
( so.Plot(penguins, x="body_mass_g") .add(so.Bars(), so.Hist()) # Histogram; x값을 bins으로 나누어 count를 계산!# .Bars()는 .Bar()에 비해 연속변수에 더 적합: 얇은 경계선으로 나란히 붙혀서 그려짐)
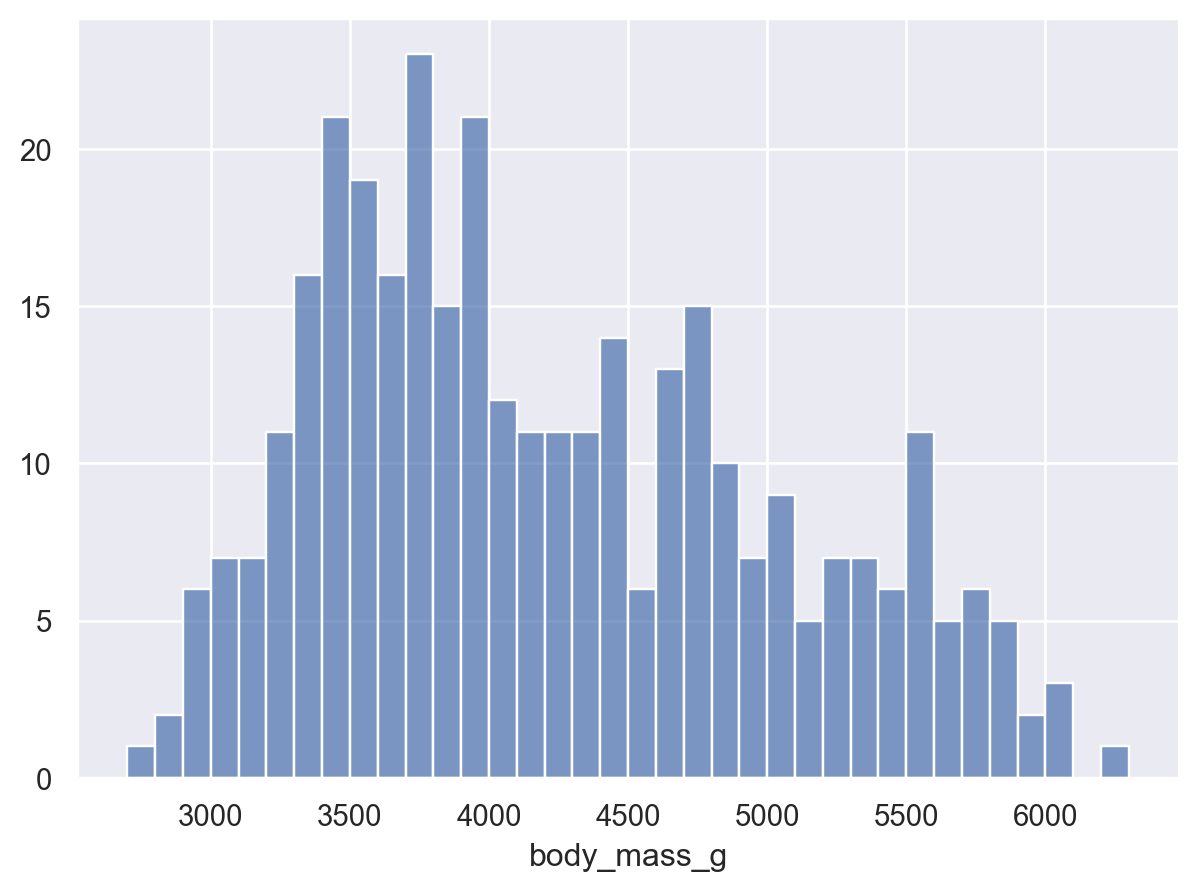
( so.Plot(penguins, x="body_mass_g") .add(so.Bars(), so.Hist(binwidth=100)) # binwidth vs. bins)( so.Plot(penguins, x="body_mass_g") .add(so.Bars(), so.Hist(bins=10)) # binwidth vs. bins)
(a) binwidth=100
(b) bins=10
Figure 3: binwidth vs. bins
( so.Plot(penguins, x="body_mass_g") .add(so.Bars(), so.Hist("proportion")) # 비율을 계산; stat="count"가 default)
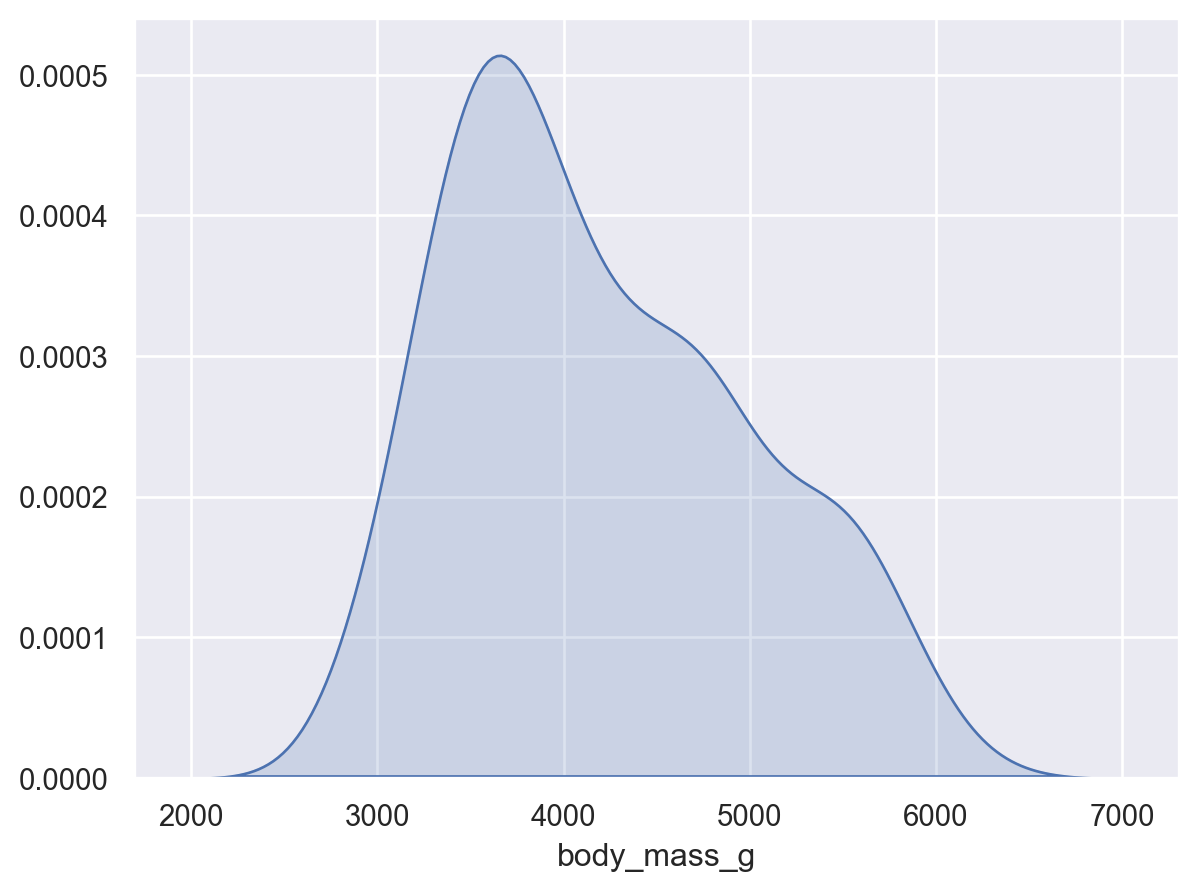
# Density plot: 넓이가 1이 되도록( so.Plot(penguins, x="body_mass_g") .add(so.Area(), so.KDE()) # Density plot)
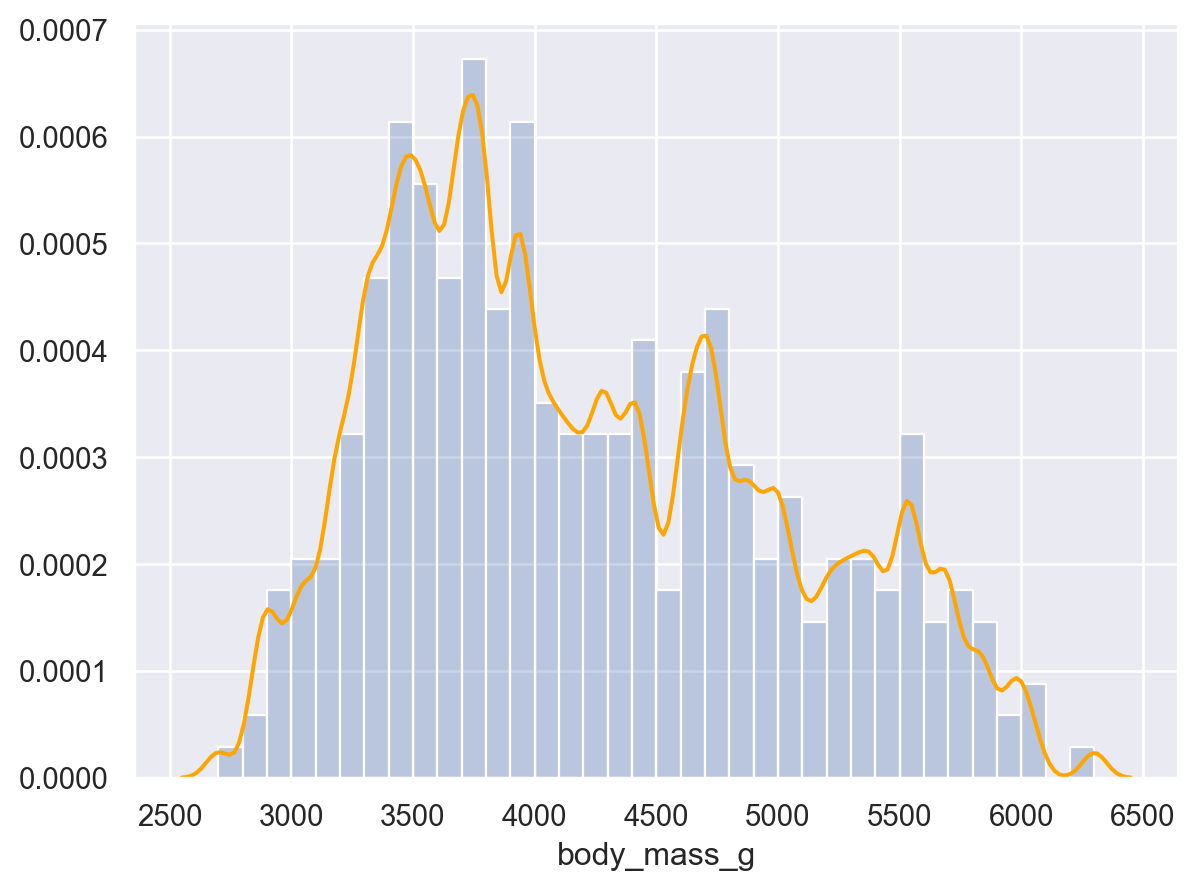
# Density plot: 넓이가 1이 되도록( so.Plot(penguins, x="body_mass_g") .add(so.Line(color="orange"), so.KDE(bw_adjust=.2)) # Density bandwidth: binwidth에 대응 .add(so.Bars(alpha=.3), so.Hist("density", binwidth=100)) # stat="density")
pandas의 method를 이용한 여러 히스토그램 그리기
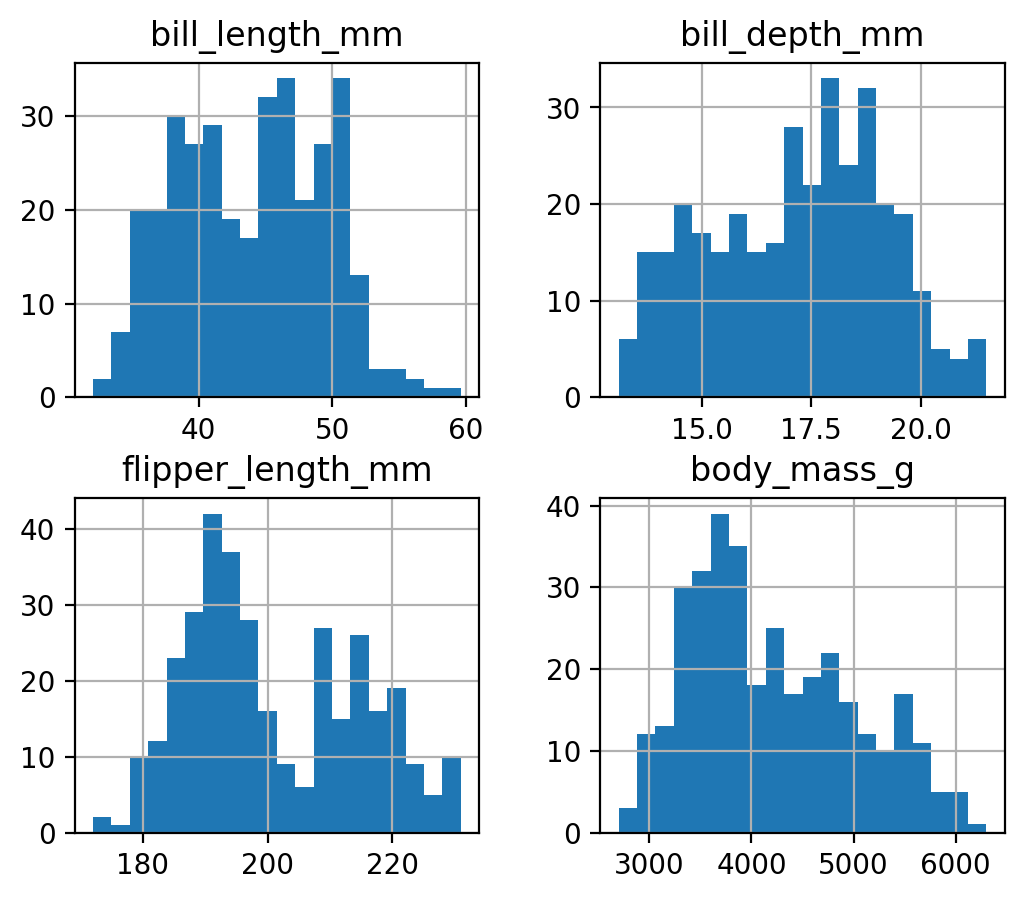
pandas의 hist() method: 모든 연속 변수에 대해 histogram을 그림
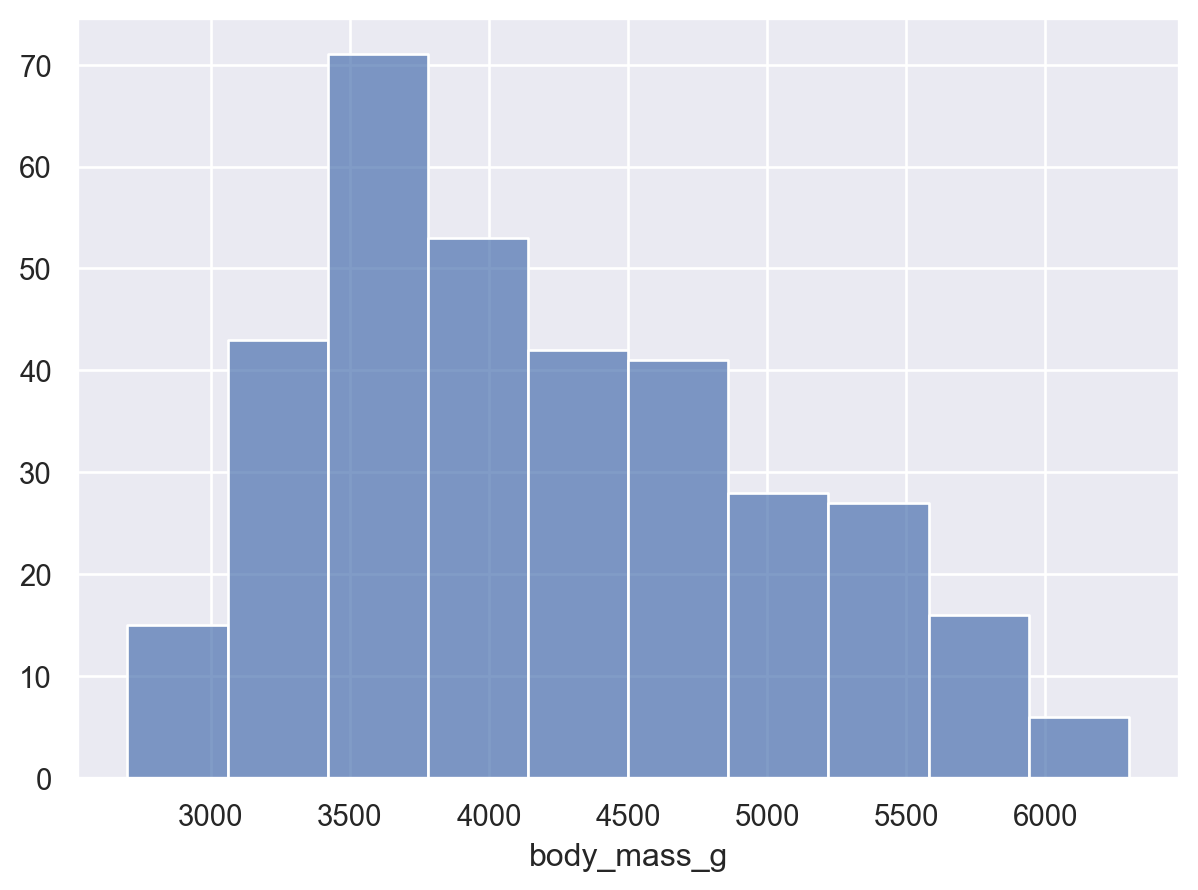
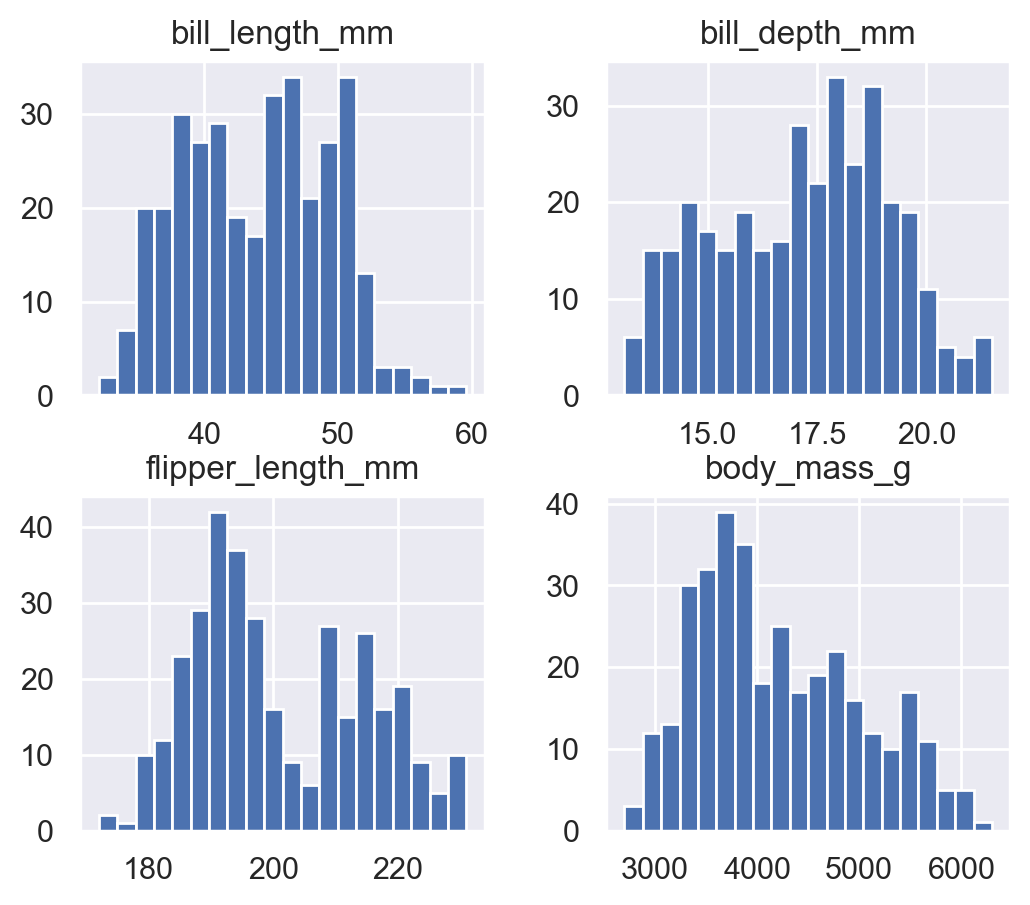
penguins.hist(bins=20);# 파라미터 figsize=(6, 5)# 세미콜론(;) 대신 plt.show() 쓸수도 있음
seaborn 스타일로 histogram 그리기
sns.set_theme()penguins.hist(bins=20);
sns.set_theme(): set aspects of the visual theme for all matplotlib and seaborn plots. hist() 메서드가 matplotlib 대신 seaborn 스타일로 그려짐.
Visualizing relationships
A numerical and a categorical variable
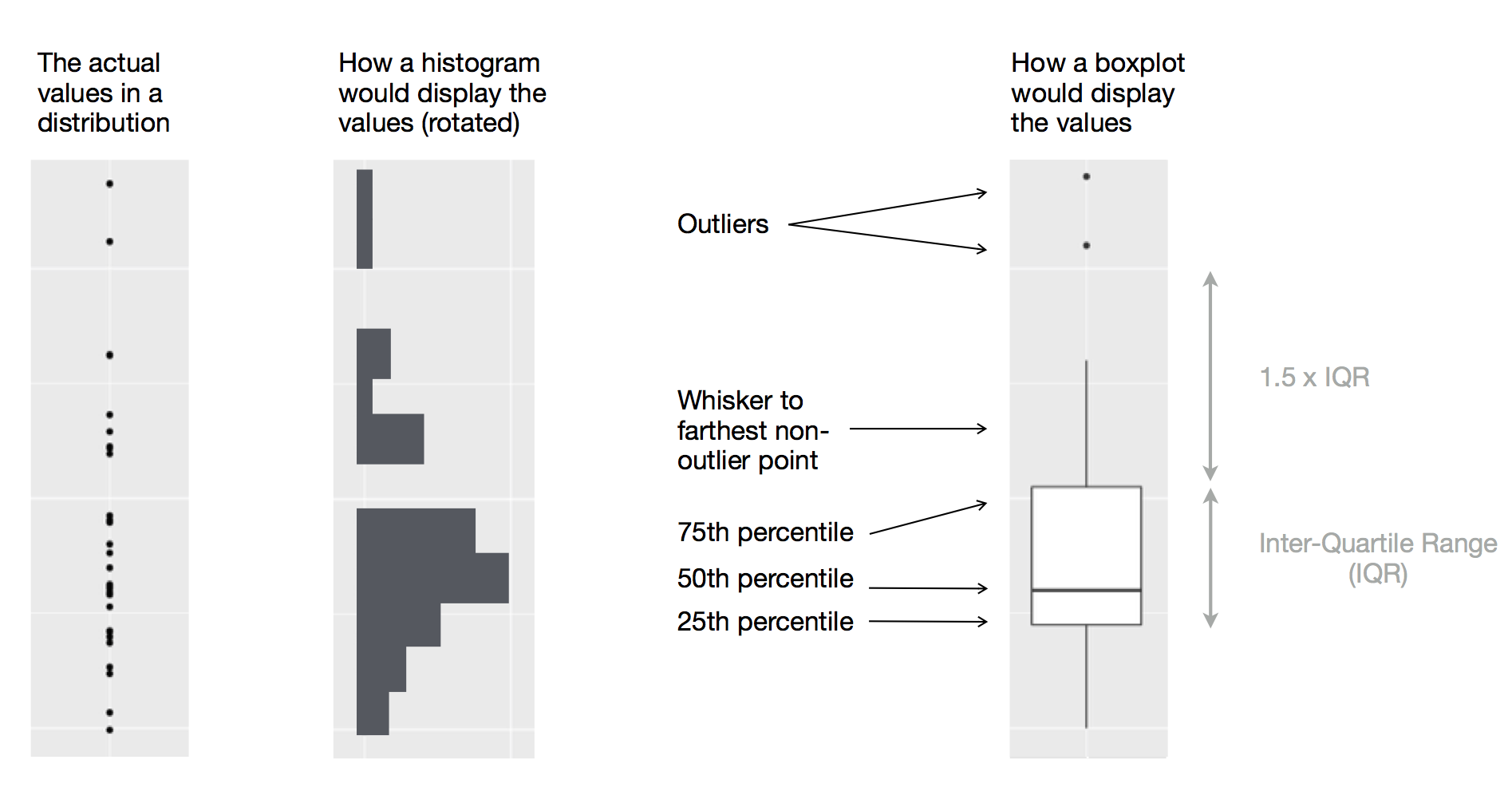
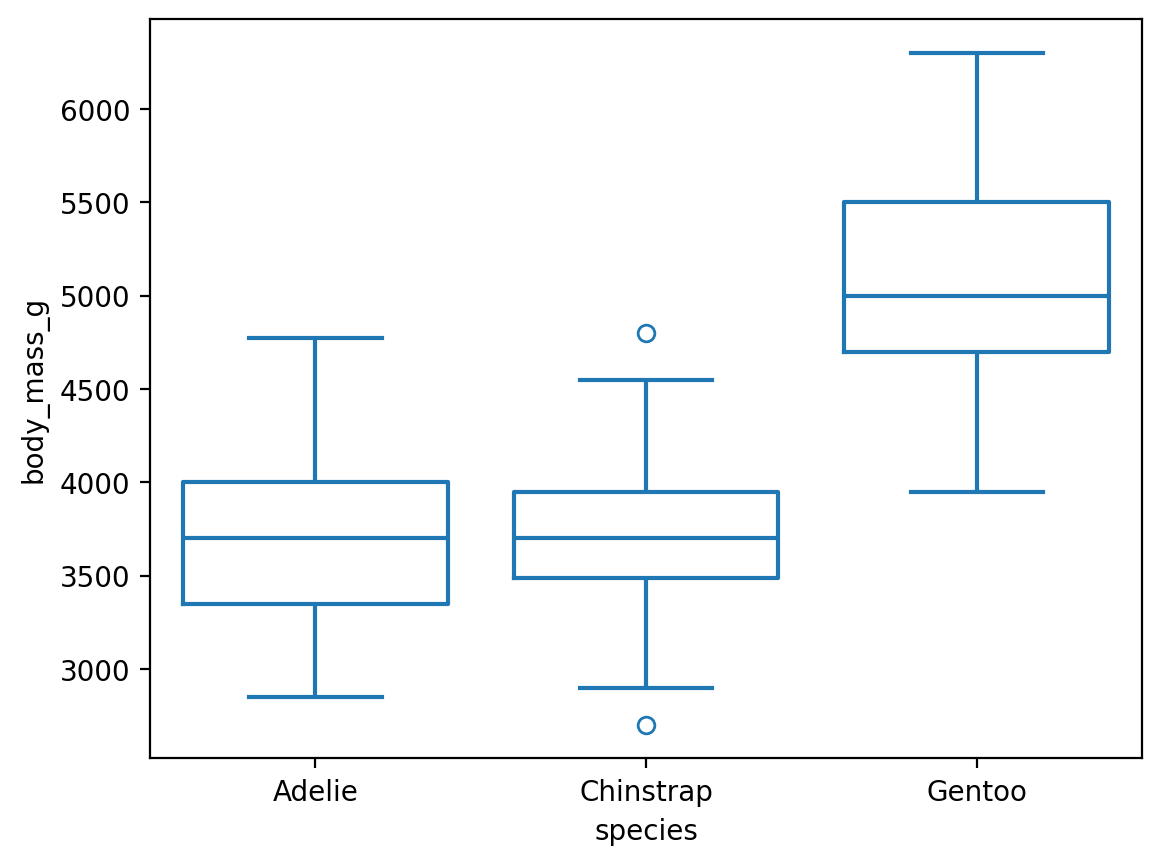
Boxplot
Grouped distribution: histogram, frequency polygon, density plot
Boxplot
source: R for Data Science
각각에 상응하는 분포(KDE, kernel density plot)
한쪽으로 쏠린 정도; 왜도(skewness)
퍼져 있는 정도 정도; 표준편차
정규분포로부터 벗어나는 정도: 첨도(kurtosis)
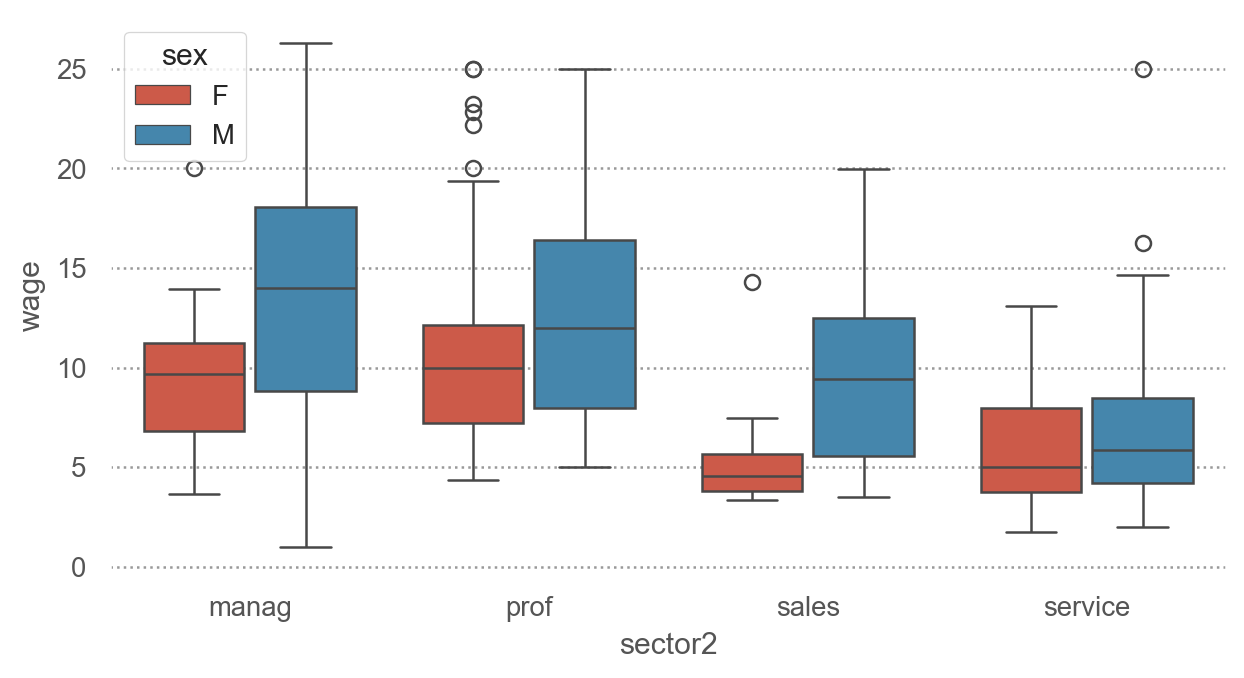
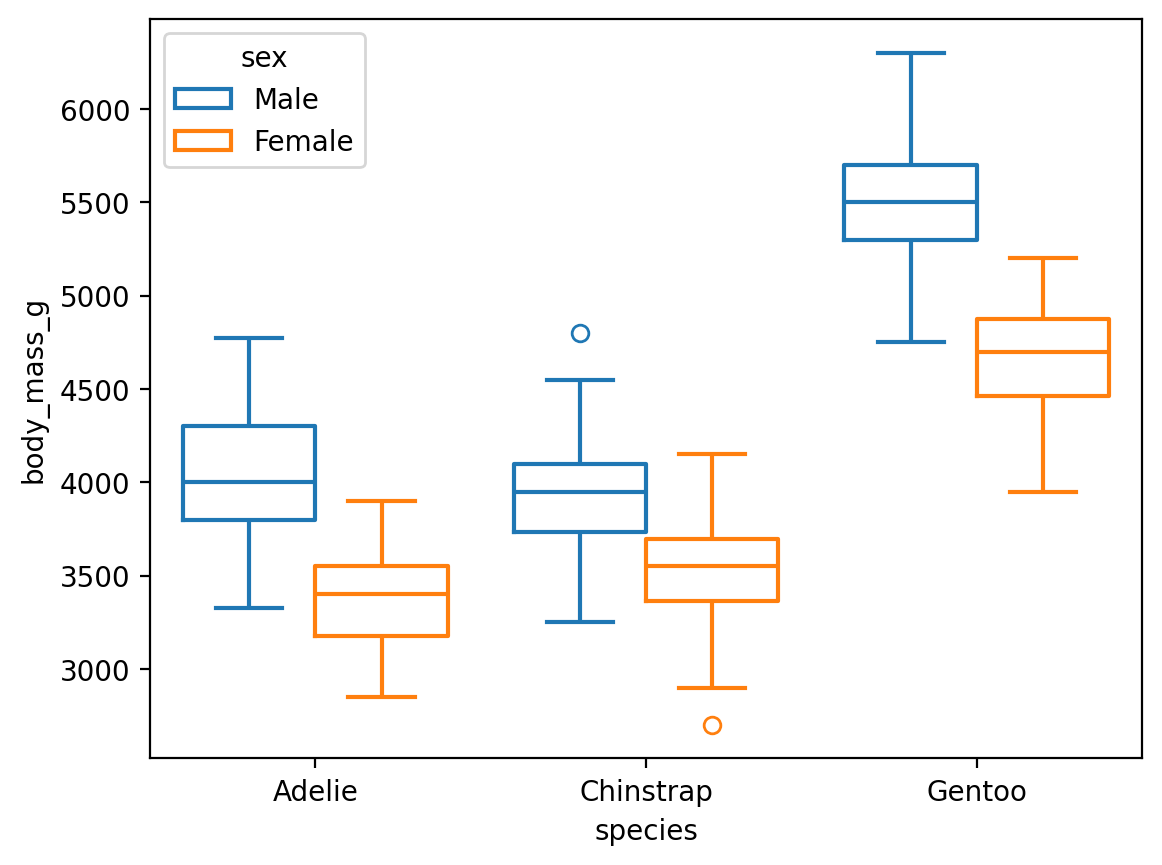
Seaborn 함수인 boxplot()을 이용하면,
sns.boxplot(penguins, x="species", y="body_mass_g", fill=False);# fill: box의 색을 채울지 여부
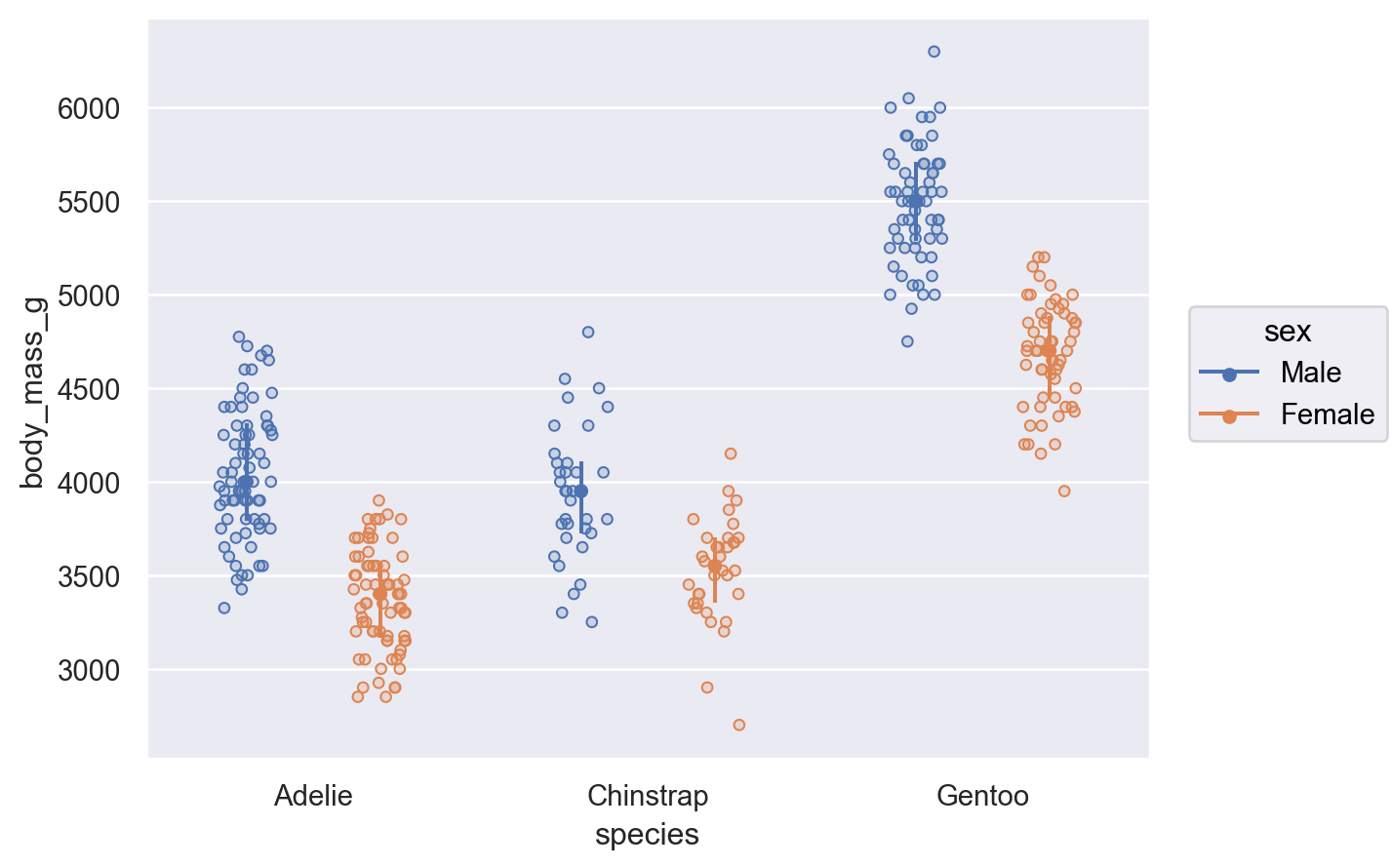
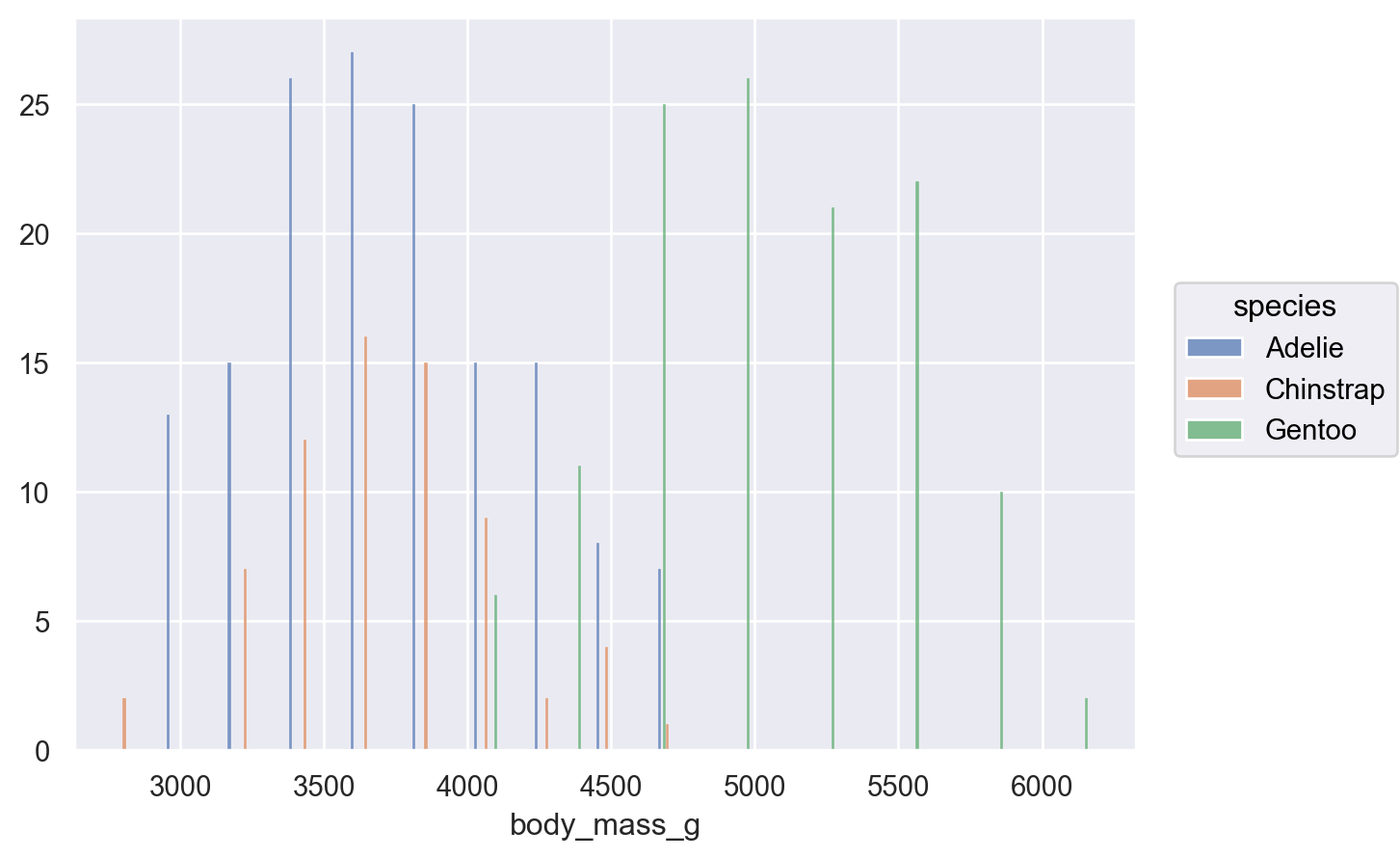
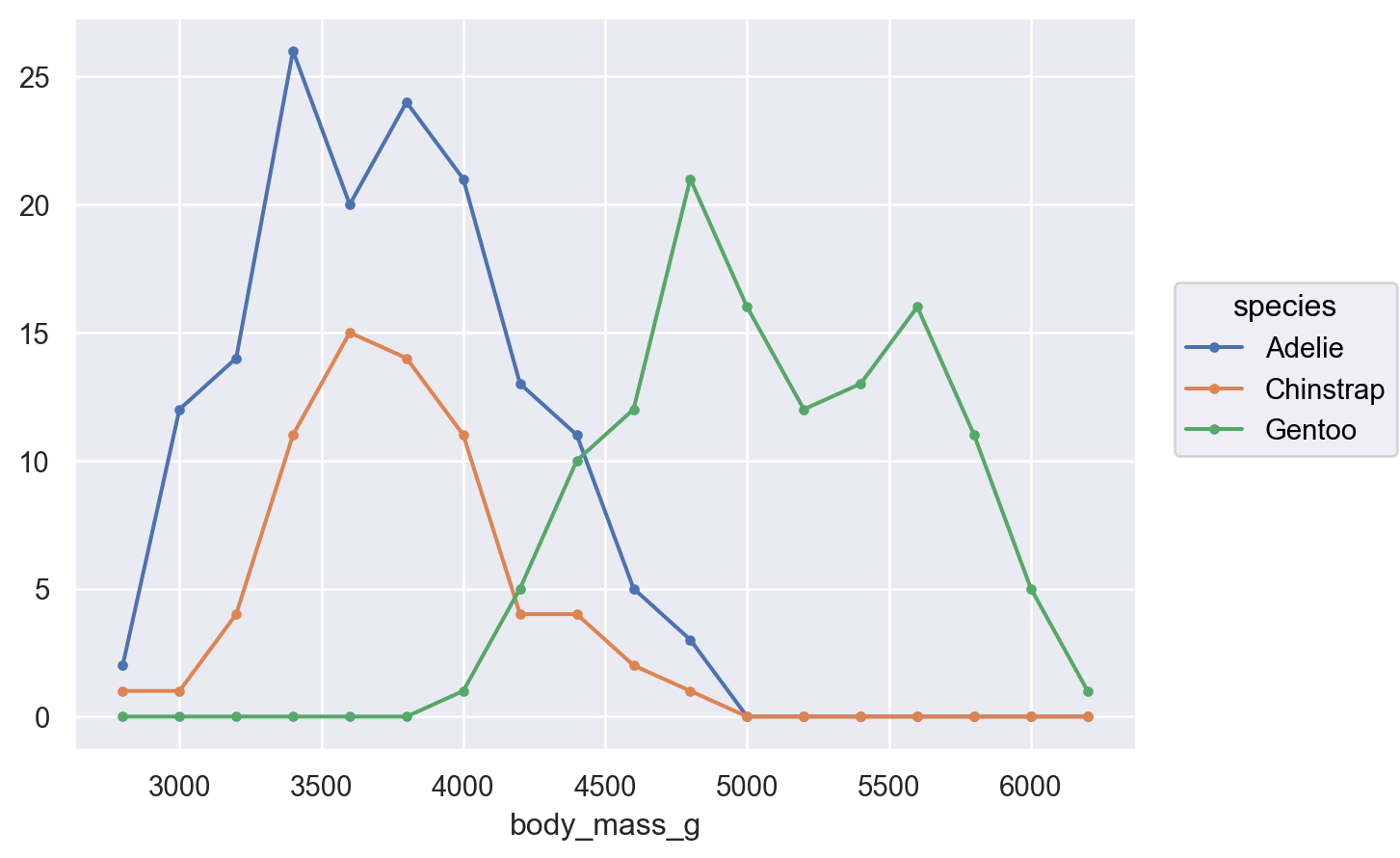
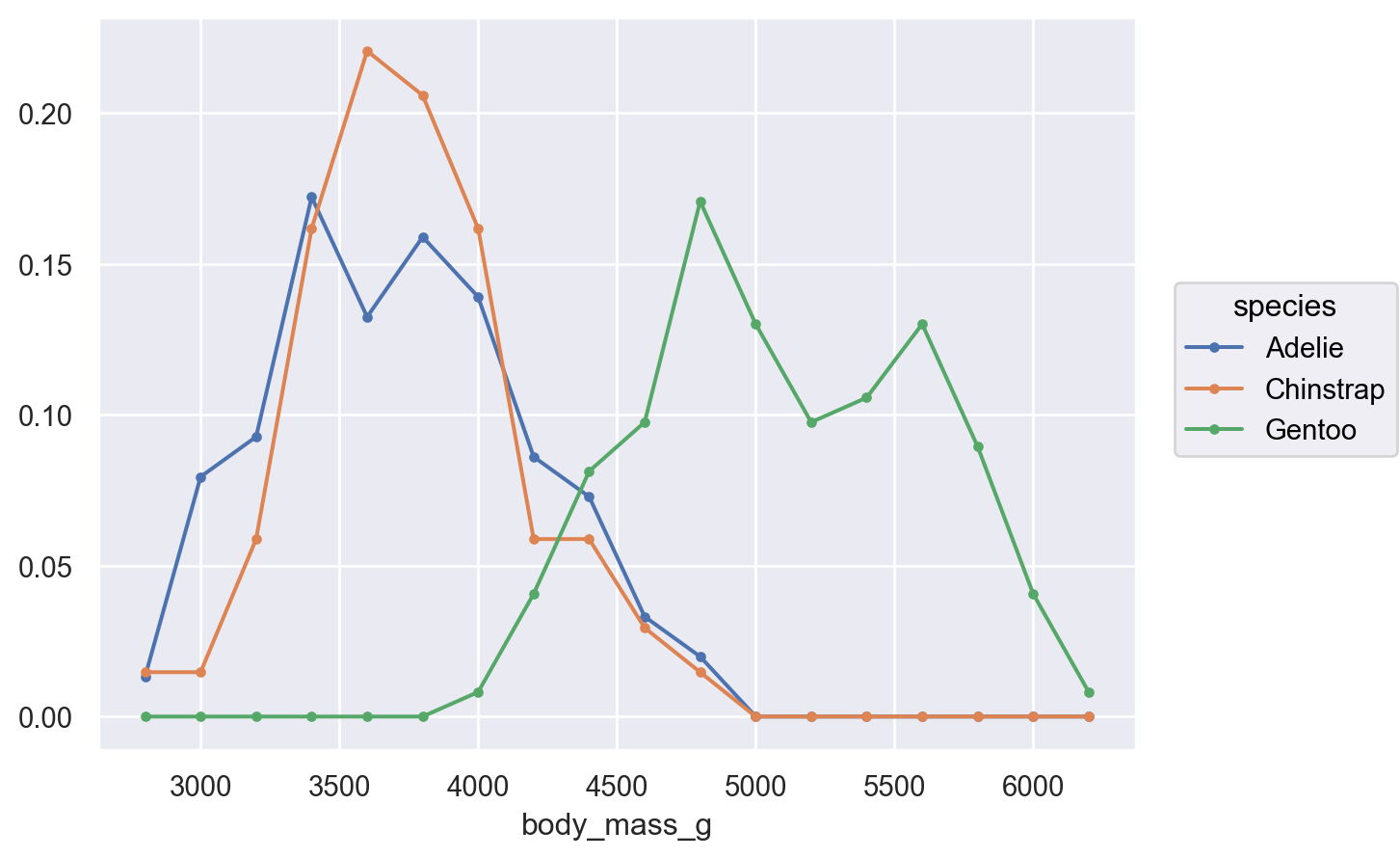
# 비율로 표시 & 각 카테고리/레벨 별로 비율 계산( so.Plot(penguins, x="body_mass_g", color="species") .add( so.Line(marker="."), so.Hist(binwidth=200, stat="proportion", common_norm=False) ) )
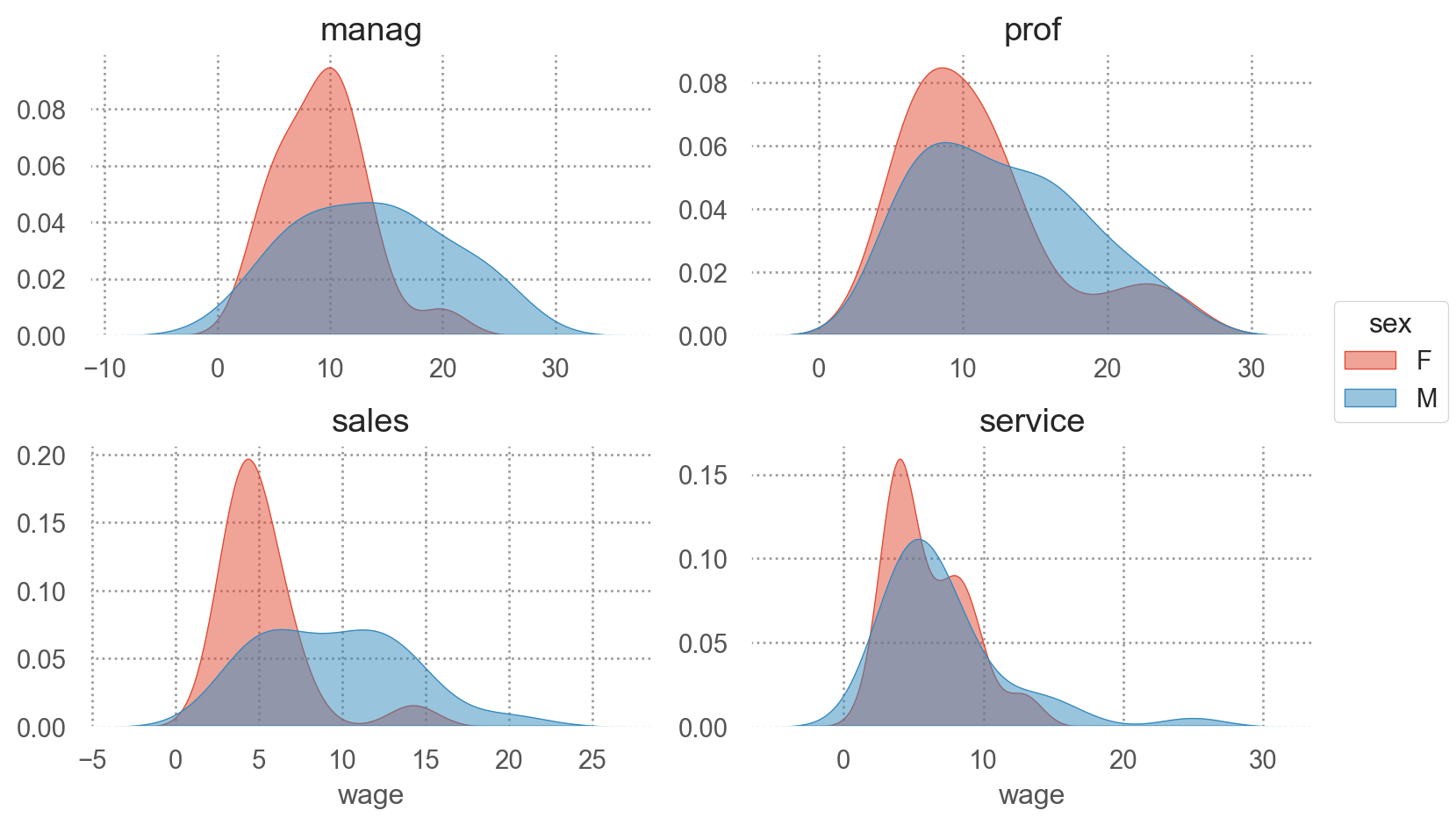
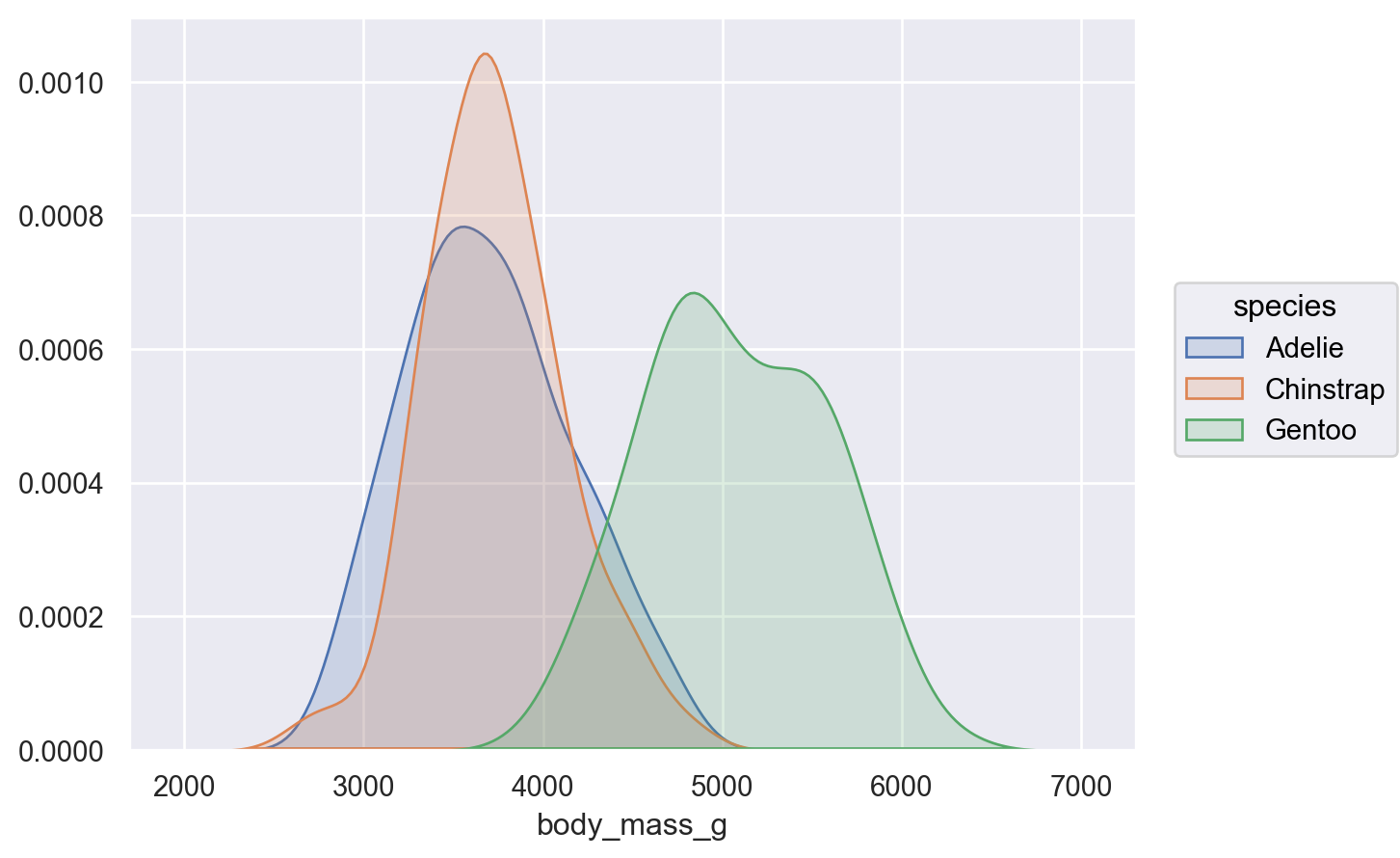
Density plot
( so.Plot(penguins, x="body_mass_g", color="species") .add(so.Area(), so.KDE(common_norm=False)) # Density plot, species별로 넓이가 1이 되도록)
Two categorical variables
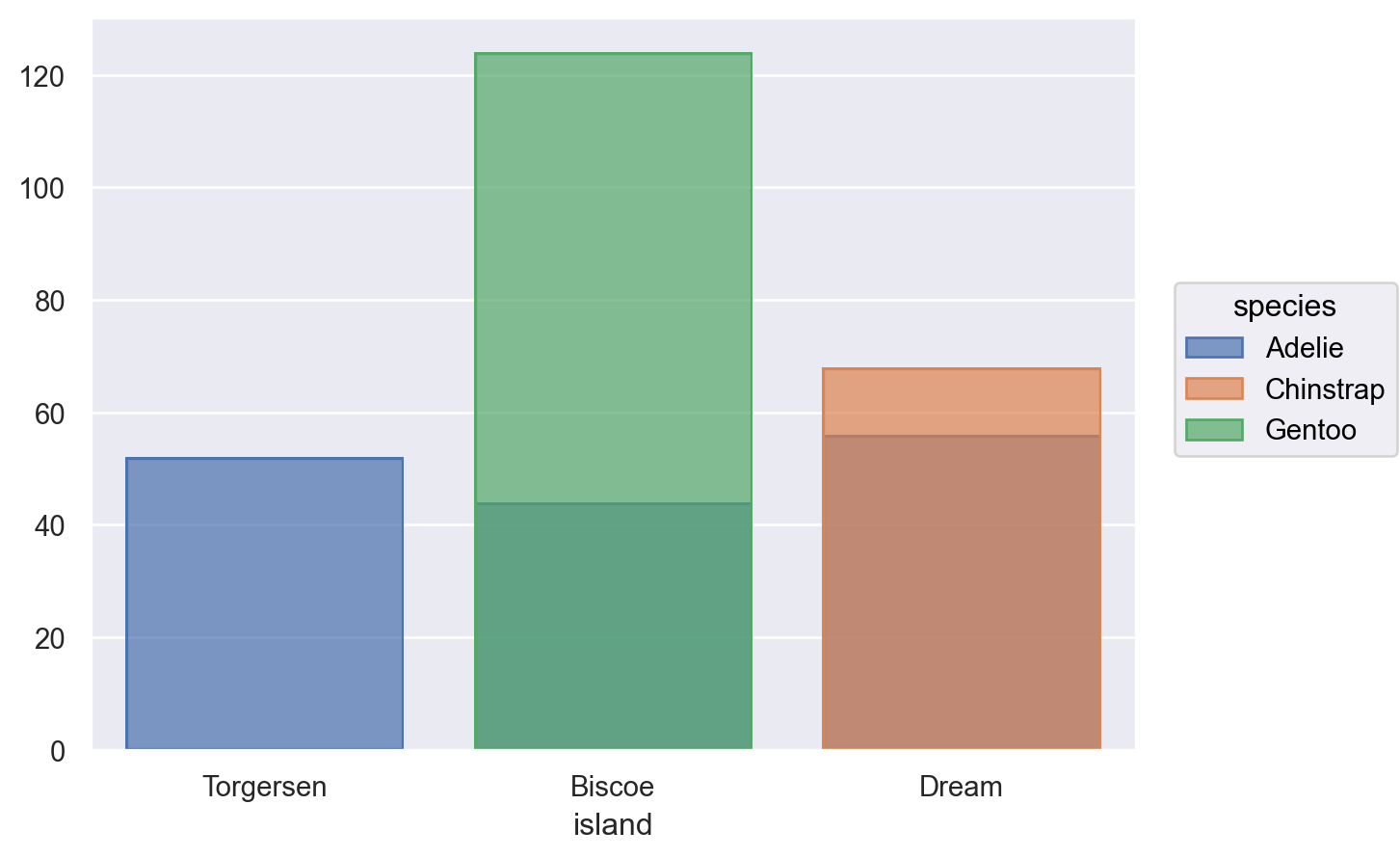
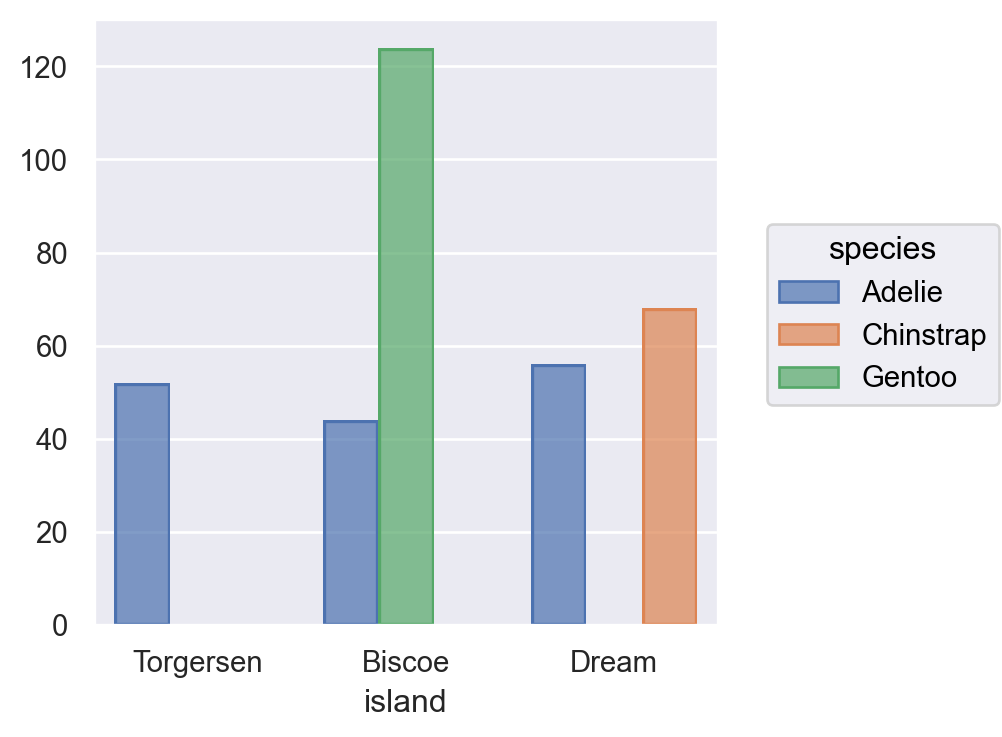
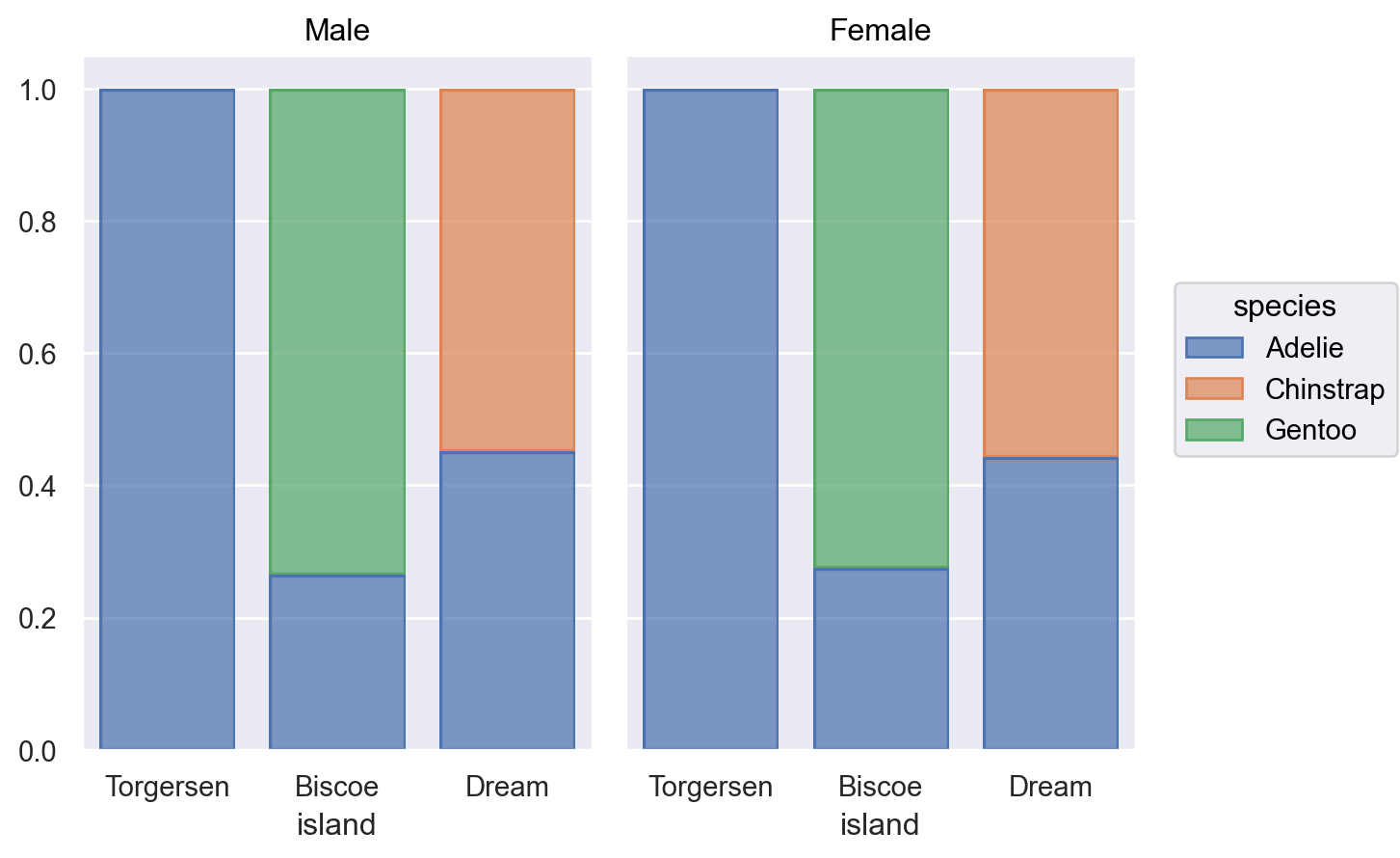
p = so.Plot(penguins, x="island", color="species")p.add(so.Bar(), so.Count()) # Bar() mark + Count() transformation
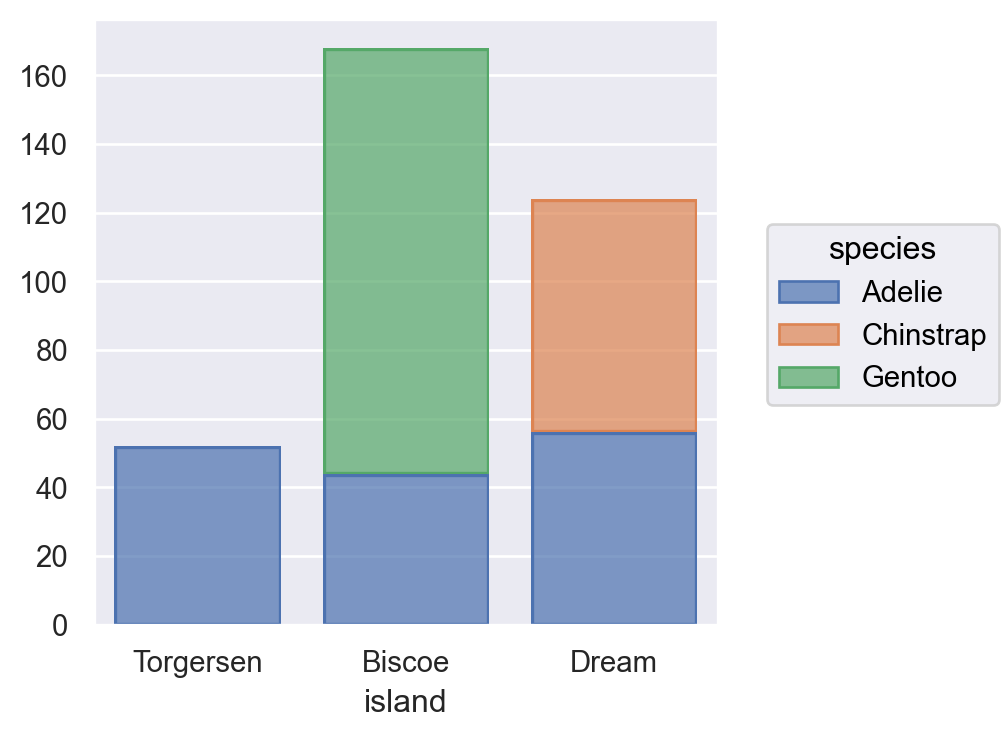
p.add(so.Bar(), so.Count(), so.Dodge()) # 나란히 표시p.add(so.Bar(), so.Count(), so.Stack()) # stacking
(a) dodge
(b) stack
Figure 4: dodge vs. stack
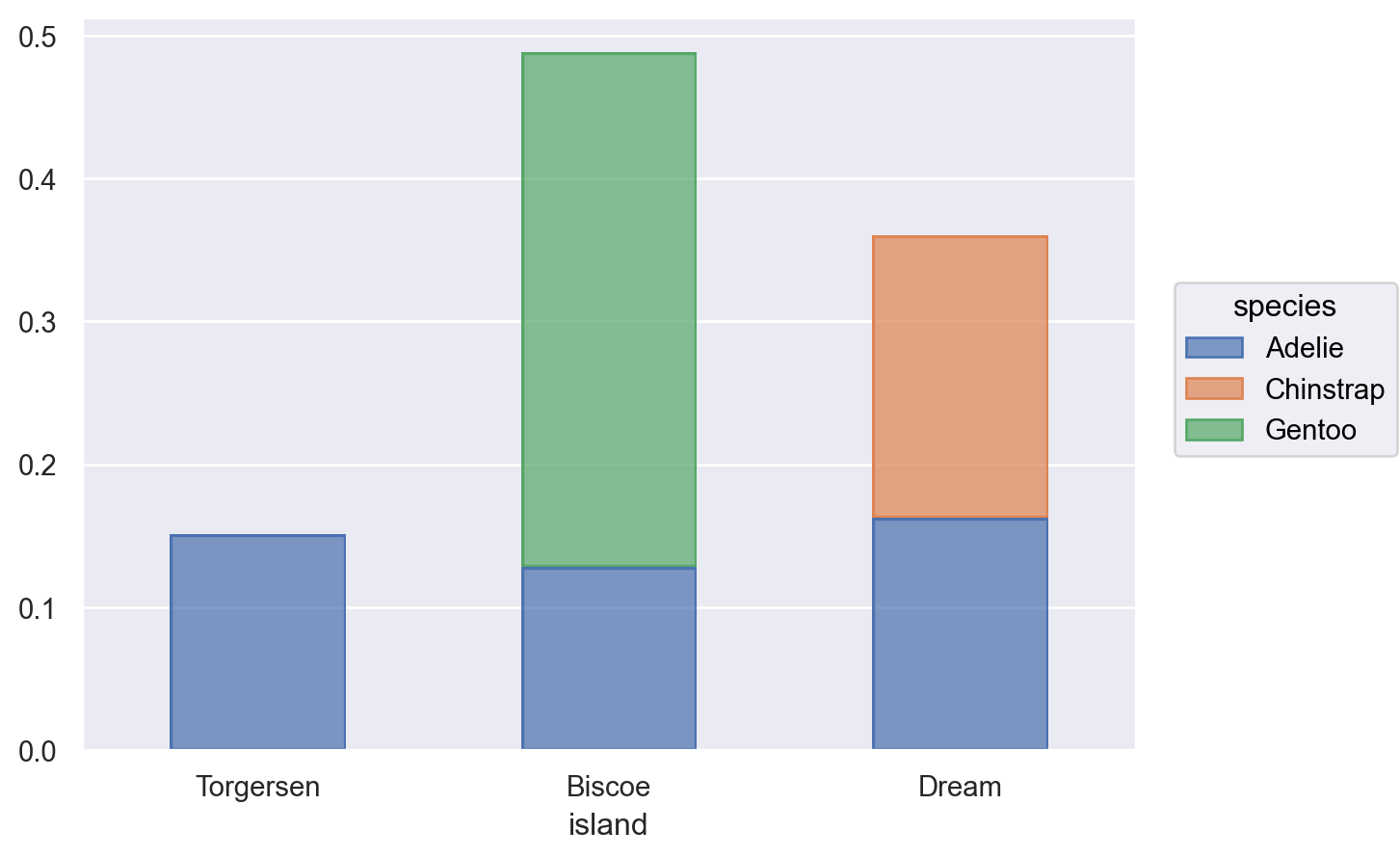
Count 대신 proportion을 표시하는 경우: Hist()를 사용 Count()는 Hist(stat="count")와 동일함.
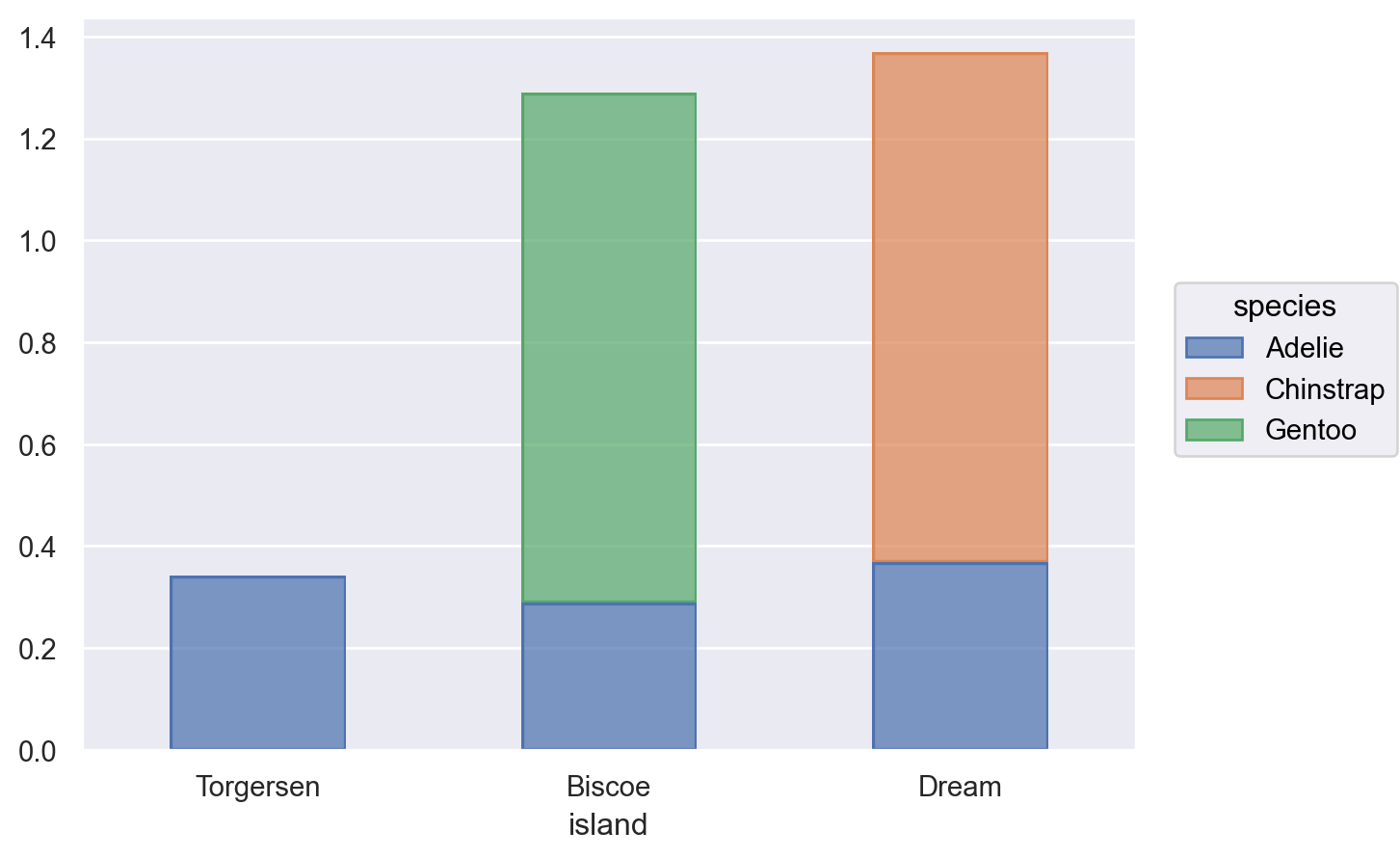
# 각 비율값의 합이 1이 되도록, 즉 모든 카테고리에 걸쳐 normalizep.add( so.Bar(width=.5), so.Hist("proportion"), # proportion; stat="count"로 하면 앞서 so.Count()와 동일 so.Stack() # stacking)
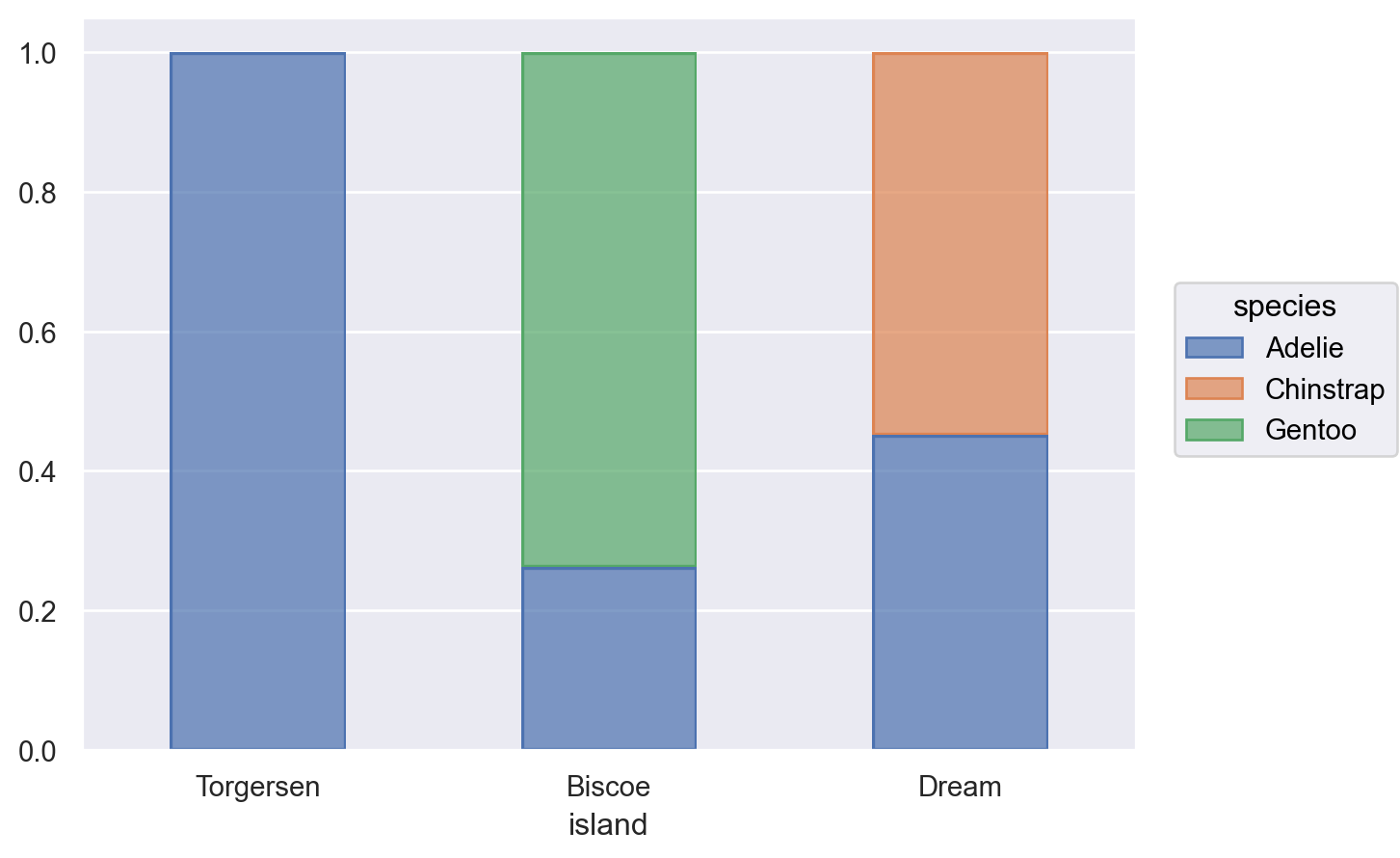
# x축 기준으로 normalizep.add( so.Bar(width=.5), so.Hist("proportion", common_norm=["x"]), # proportion; so.Stack() # stacking)# warning이 뜰 수 있음!
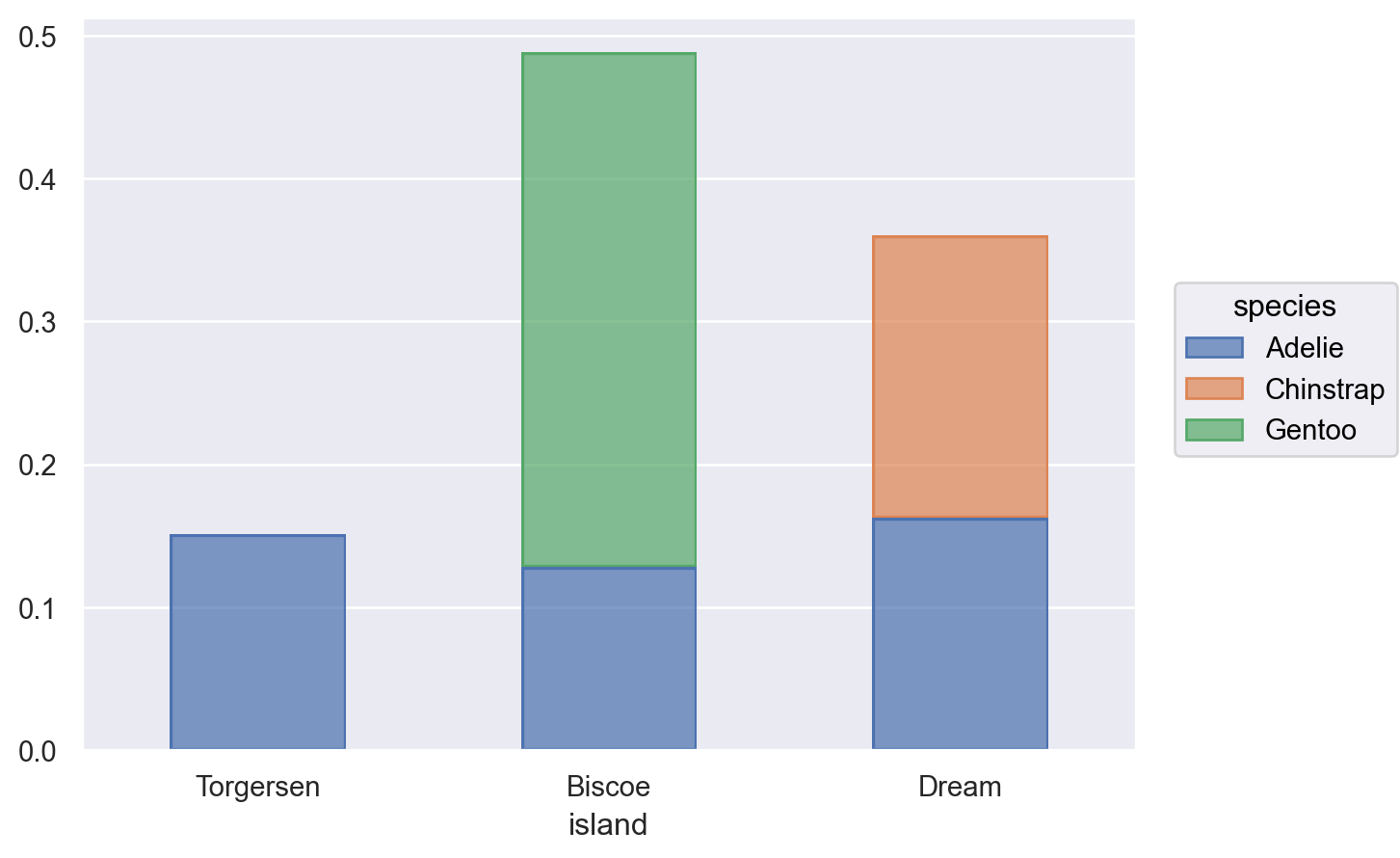
# 각 비율값의 합이 1이 되도록, 즉 모든 카테고리에 걸쳐 normalizep.add( so.Bar(width=.5), so.Hist("proportion", common_norm=True), # default so.Stack())# 각 species별로 normalize p.add( so.Bar(width=.5), so.Hist("proportion", common_norm=False), so.Stack())
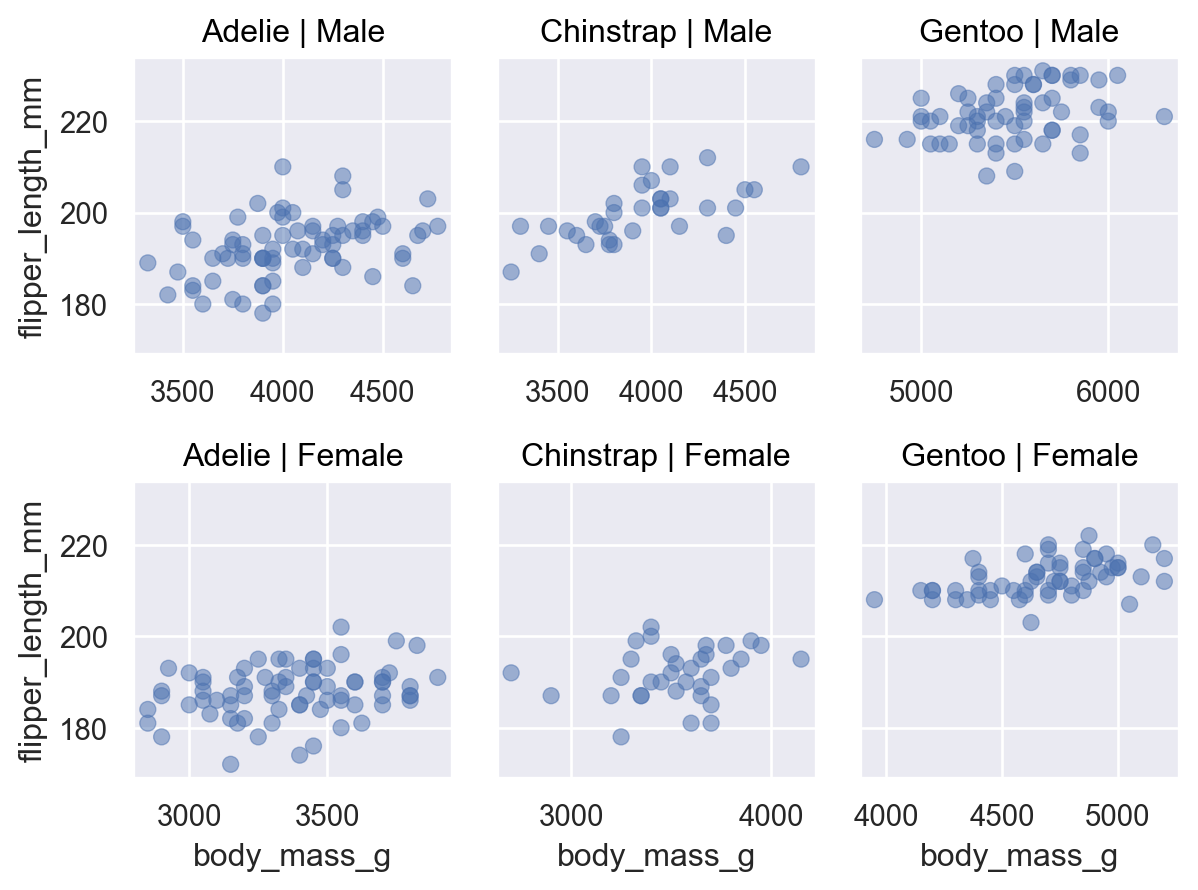
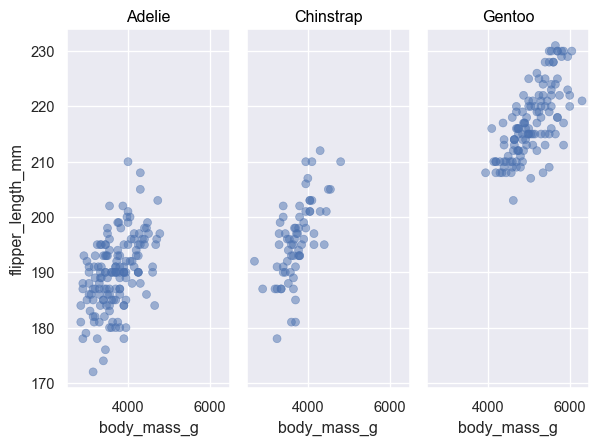
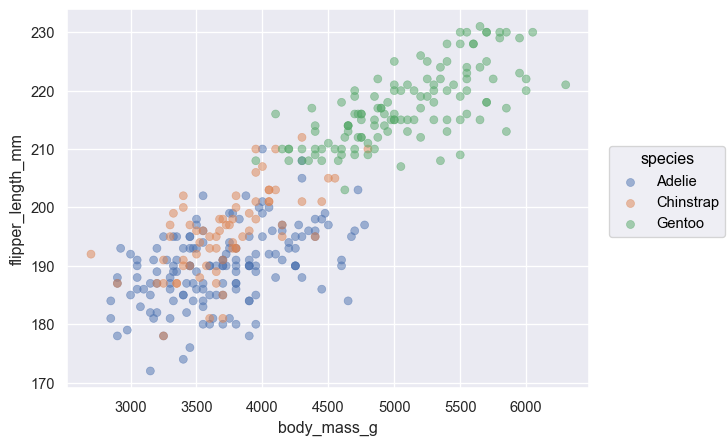
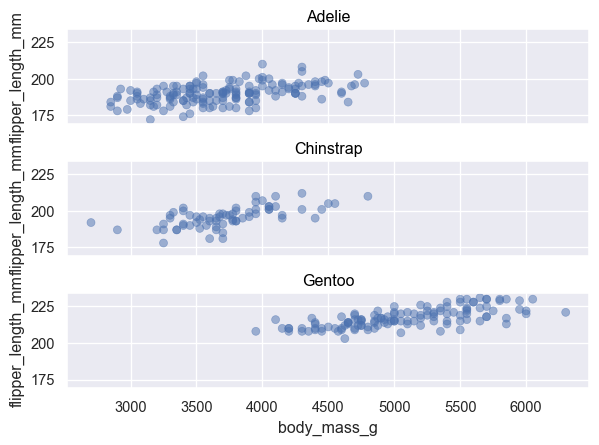
Two numerical variables
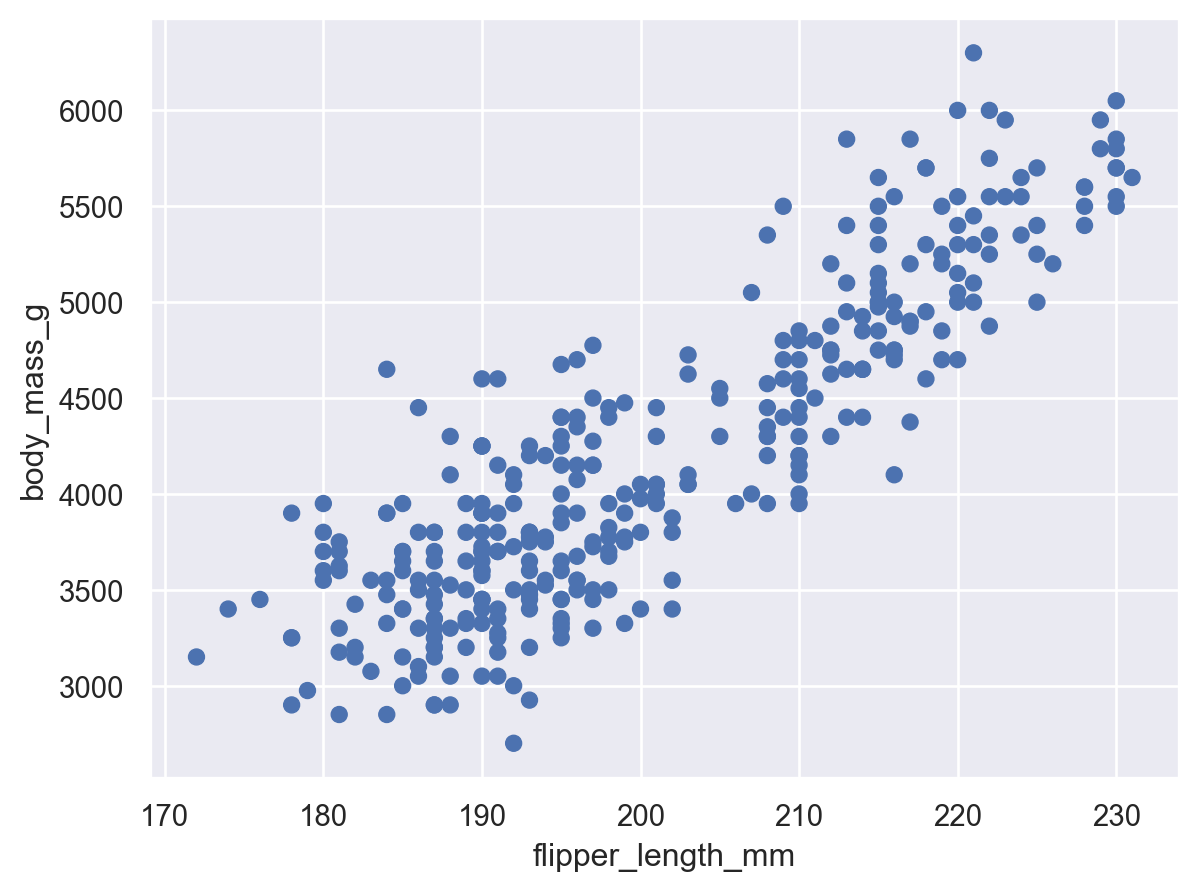
Scatterplot
( so.Plot(penguins, x="flipper_length_mm", y="body_mass_g") .add(so.Dot()) # overplotting에는 so.Dots()가 유리 )